Essence
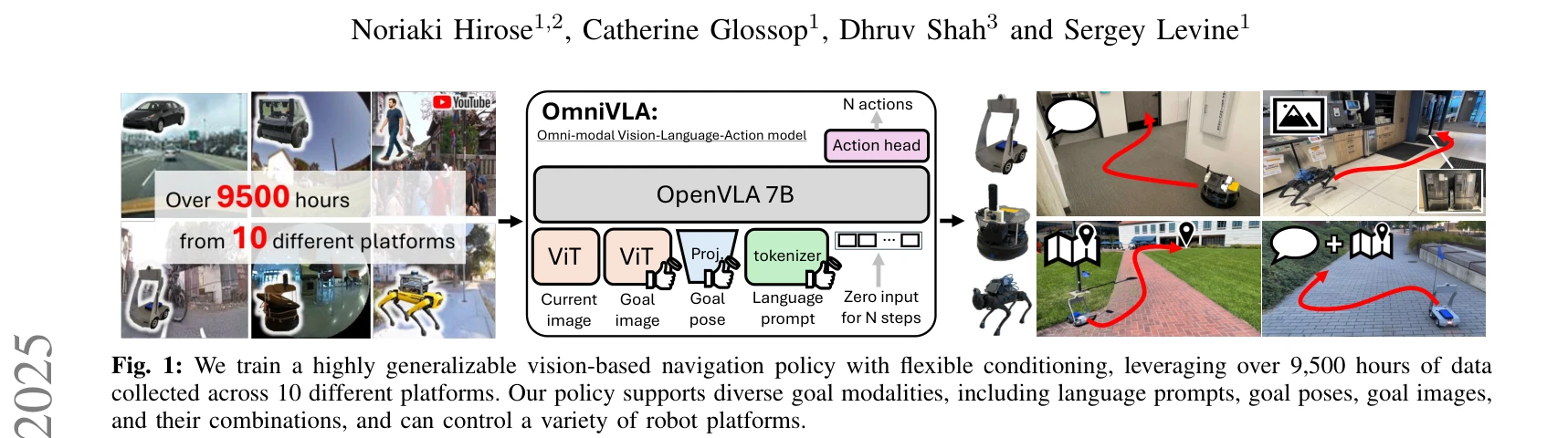
Fig. 1: We train a highly generalizable vision-based navigation policy with flexible conditioning, leveraging over 9,500
OmniVLA는 2D 포즈, egocentric 이미지, 자연어 등 다양한 모달리티로 조건화된 목표를 처리할 수 있는 omni-modal vision-language-action 모델로, 9,500시간 이상의 다중 플랫폼 로봇 네비게이션 데이터로 학습되어 강력한 일반화 성능을 달성한다.