저자: Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, Brian Ichter | 날짜: 2022-07-12 | URL: https://arxiv.org/abs/2207.05608 📄 PDF
Essence
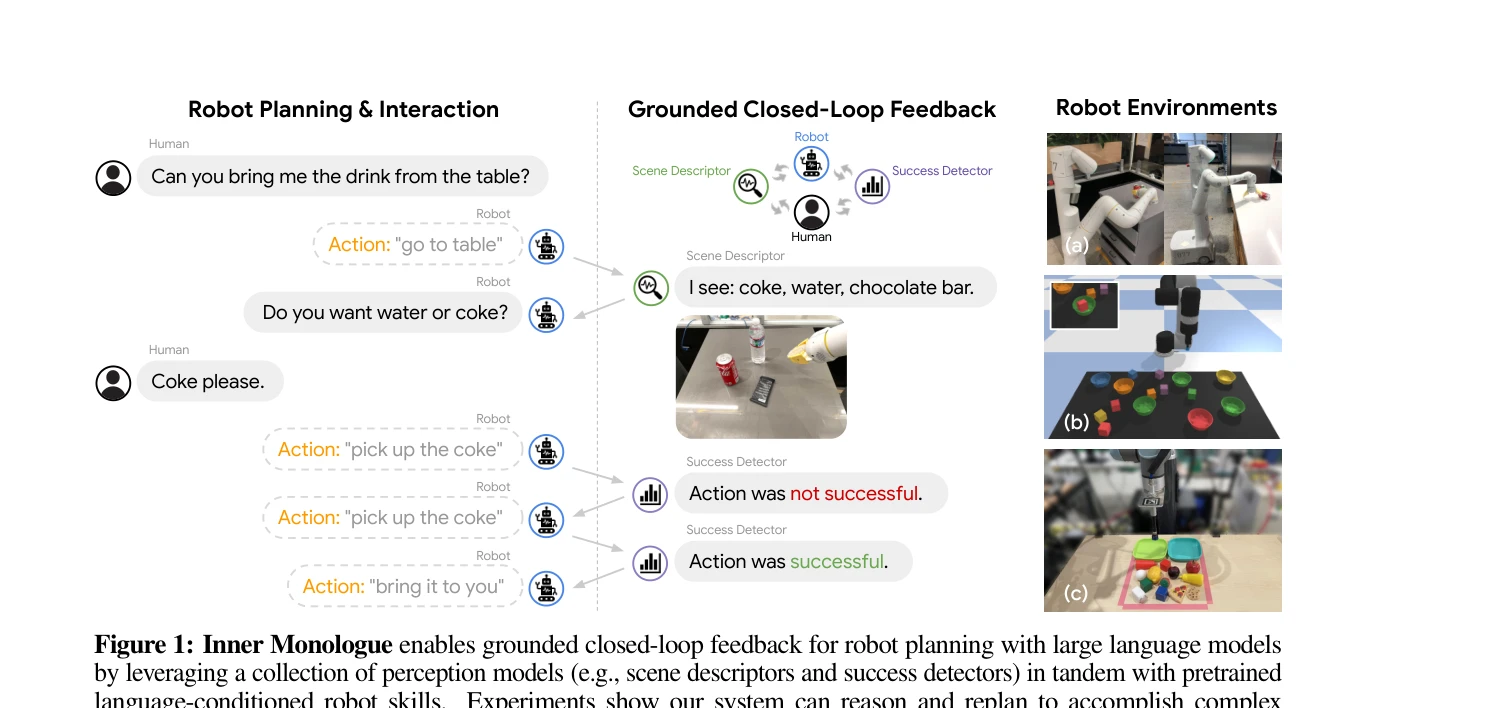
Figure 1: Inner Monologue enables grounded closed-loop feedback for robot planning with large language models
LLM을 로봇 제어에 활용할 때, 환경 피드백을 자연어로 주입하여 LLM이 '내적 독백(inner monologue)'을 형성하게 함으로써 폐루프 계획 및 추론을 가능하게 한다. 추가 학습 없이 프롬프팅만으로 복잡한 장기 조작 작업을 수행할 수 있음을 보여준다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM 기반 로봇 계획에 폐루프 피드백을 자연어로 통합하는 창의적이고 실용적인 접근을 제시하며, 추가 학습 없이도 복잡한 실제 작업을 수행 가능함을 다수의 실험으로 입증했다. 다만 perception 피드백의 품질 의존성과 LLM의 고비용·지연 문제가 추후 개선 과제이다.

