Essence
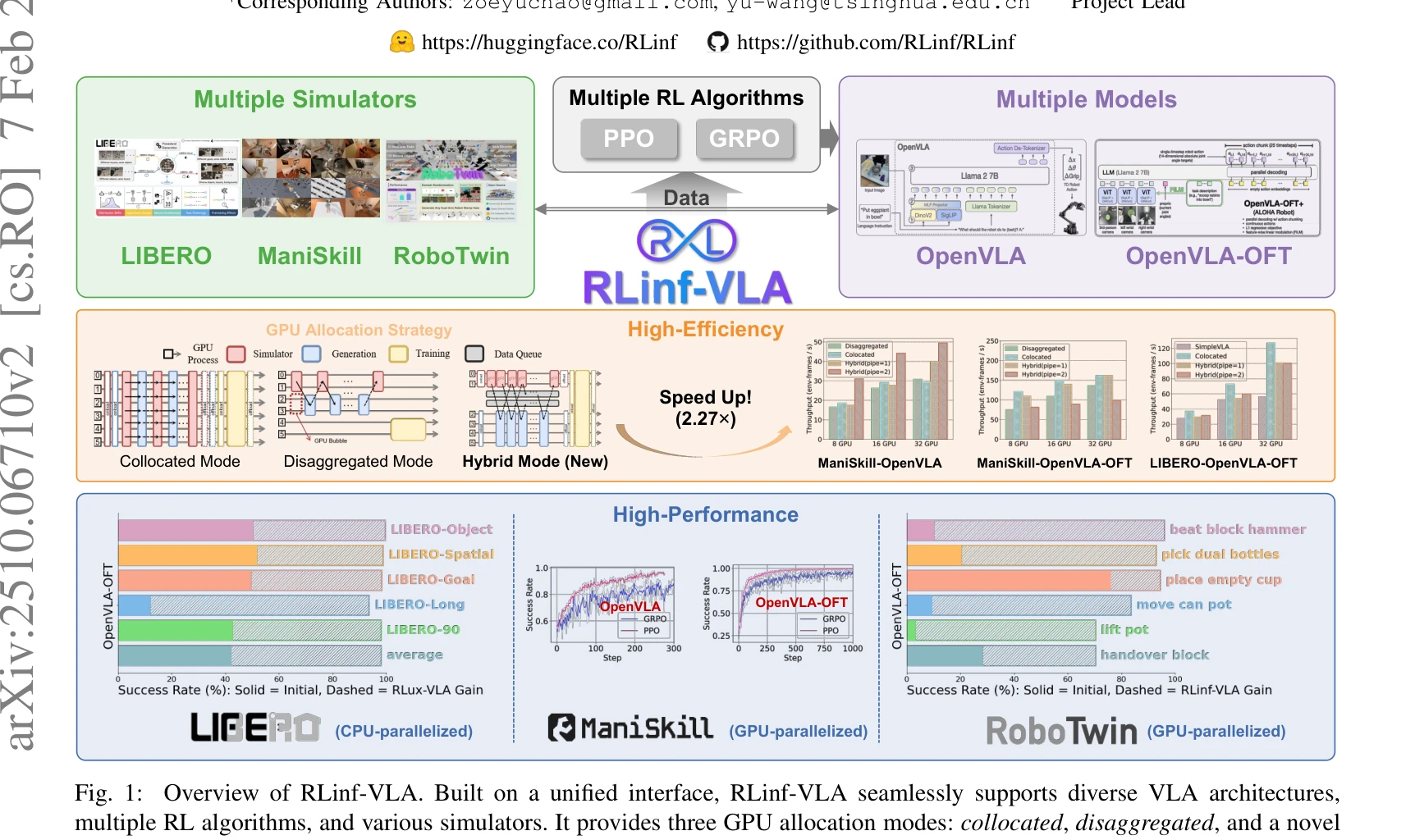
Fig. 1:
RLinf-VLA는 Vision-Language-Action 모델의 강화학습 훈련을 위한 통합되고 효율적인 프레임워크로, 다양한 VLA 아키텍처, RL 알고리즘, 시뮬레이터를 지원하며 GPU 할당 최적화를 통해 2.27배 속도 향상을 달성한다.
저자: Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Peihong Wang, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, Zhihao Liu, Kang Chen, Wenhao Tang, Quanlu Zhang, Weinan Zhang, Chao Yu, Yu Wang | 날짜: 2025-10-08 | URL: https://arxiv.org/abs/2510.06710 📄 PDF
Fig. 1:
RLinf-VLA는 Vision-Language-Action 모델의 강화학습 훈련을 위한 통합되고 효율적인 프레임워크로, 다양한 VLA 아키텍처, RL 알고리즘, 시뮬레이터를 지원하며 GPU 할당 최적화를 통해 2.27배 속도 향상을 달성한다.
Fig. 1:
총평: RLinf-VLA는 VLA 강화학습 연구의 단편화 문제를 해결하는 포괄적 통합 프레임워크이며, GPU 할당 최적화를 통한 실질적 효율성 개선과 강력한 실험 결과로 구체화 인텔리전스 연구의 주요 기초 시설로서의 가치를 입증한다.