저자: Jiahang Liu, Yunpeng Qi, Jiazhao Zhang, Minghan Li, Shaoan Wang, Kui Wu, Hanjing Ye, Hong Zhang, Zhibo Chen, Fangwei Zhong, Zhizheng Zhang, He Wang | 날짜: 2025-10-08 | URL: https://arxiv.org/abs/2510.07134 📄 PDF
Essence
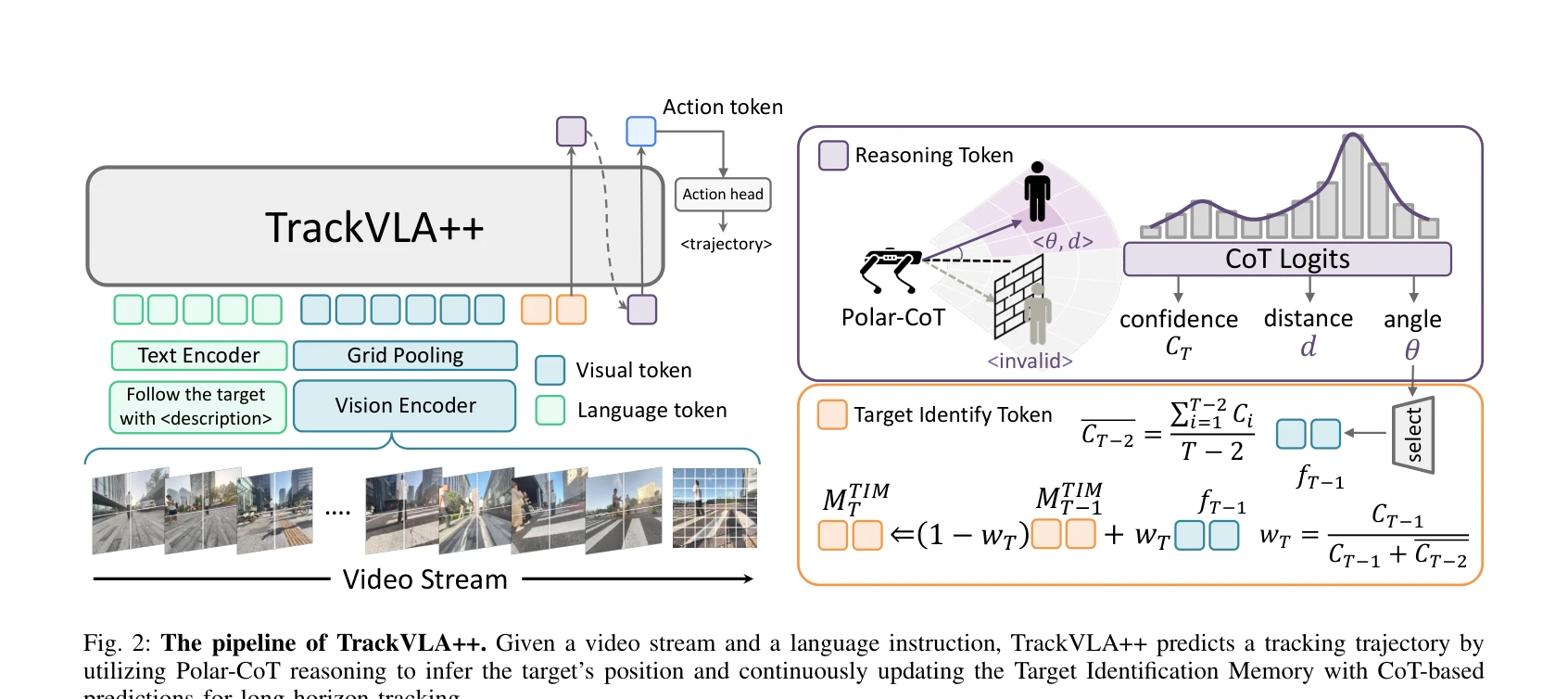
Fig. 2: The pipeline of TrackVLA++. Given a video stream and a language instruction, TrackVLA++ predicts a tracking traj
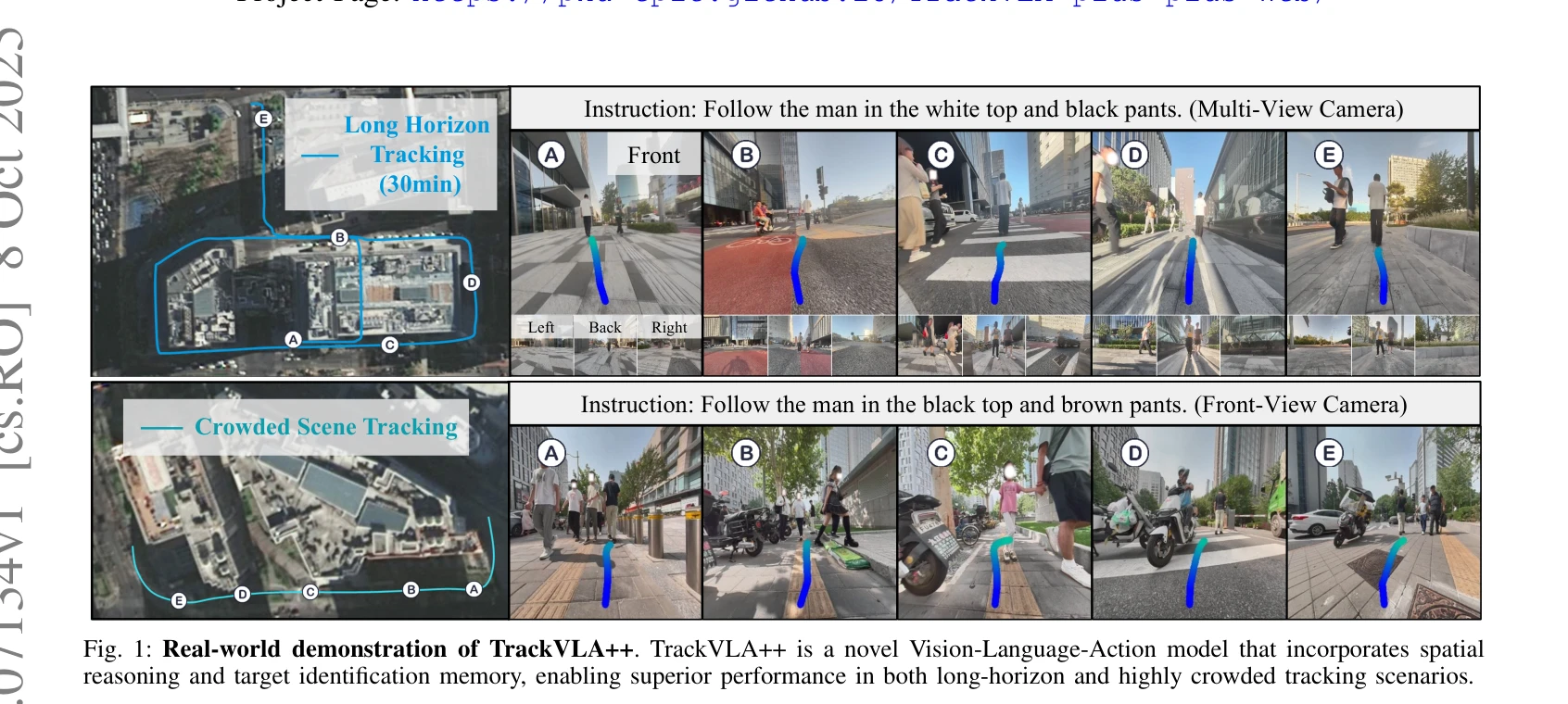
TrackVLA++는 Vision-Language-Action 모델에 Polar-CoT 공간 추론과 Target Identification Memory(TIM)를 통합하여 장시간 추적과 폐색 상황에서의 강건한 embodied visual tracking을 실현한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: TrackVLA++는 효율적인 spatial reasoning과 confidence-aware memory update로 embodied visual tracking의 실제 도전(폐색, distractors)을 우아하게 해결하며, 시뮬레이션과 실환경에서 모두 강력한 성능을 입증한 매우 우수한 연구이다.