저자: Delin Qu, Haoming Song, Qizhi Chen, Zhaoqing Chen, Xianqiang Gao, Dong Wang, Xinyi Ye, Qi Lv, Modi Shi, Guanghui Ren, Cheng Ruan, Maoqing Yao, Haoran Yang, Jiacheng Bao, Bin Zhao, Xuelong Li | 날짜: 2025-08-28 | URL: https://arxiv.org/abs/2508.21112 📄 PDF
Essence
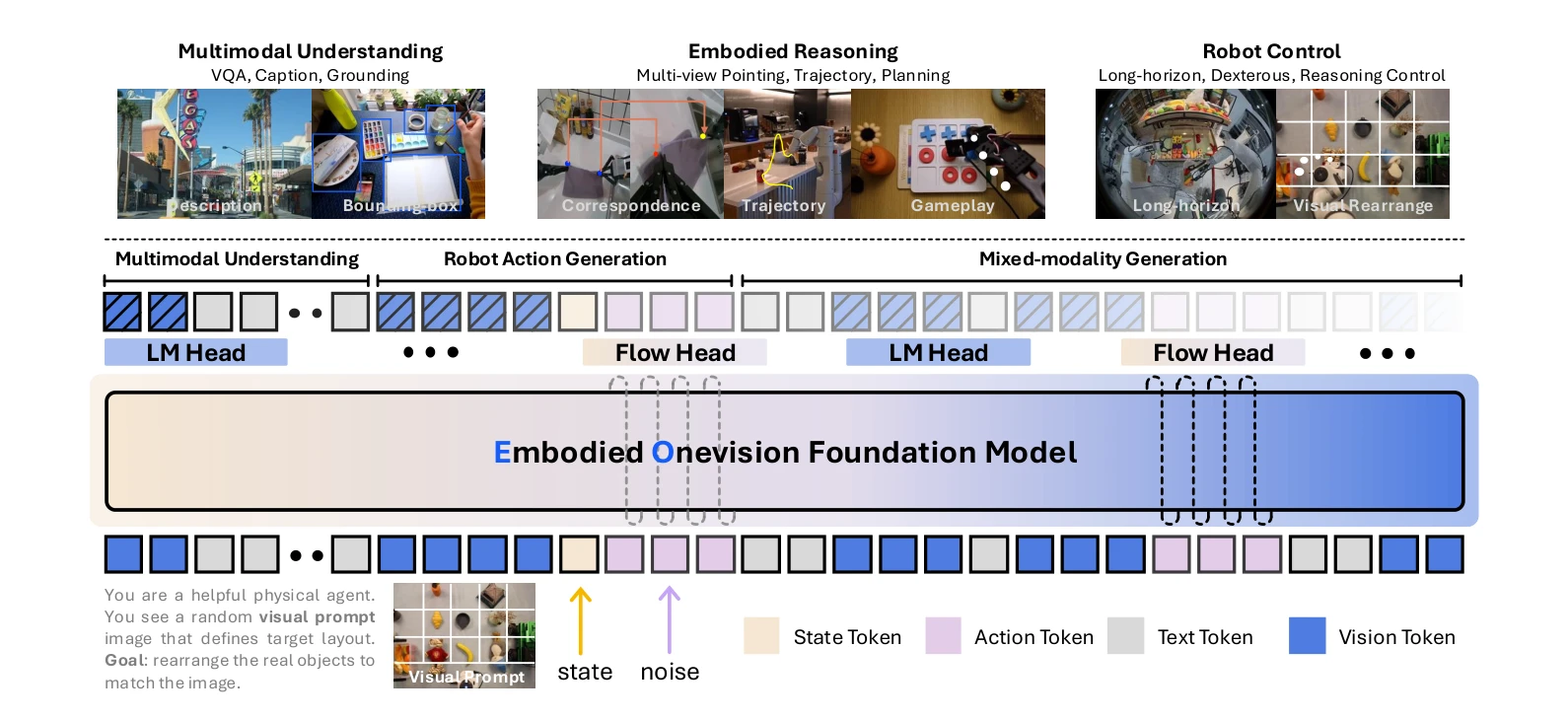
Figure 1: EO-1 Model Architecture. EO-1 model is a Vision-Language-Action (VLA) model that adopts a
EO-1은 interleaved vision-text-action 사전학습을 통해 multimodal embodied reasoning과 robot control을 통합한 unified embodied foundation model이며, 1.5M 샘플의 EO-Data1.5M 데이터셋과 함께 개발되었다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: EO-1은 interleaved vision-text-action pretraining paradigm을 통해 embodied AI의 근본적인 문제인 reasoning-acting integration을 우아하게 해결하며, 1.5M 규모의 고품질 dataset과 unified architecture의 결합으로 open-world robot control에서 significant advancement를 제시한다. 전체 toolchain의 open release는 community에 substantial contribution을 제공한다.
