Essence
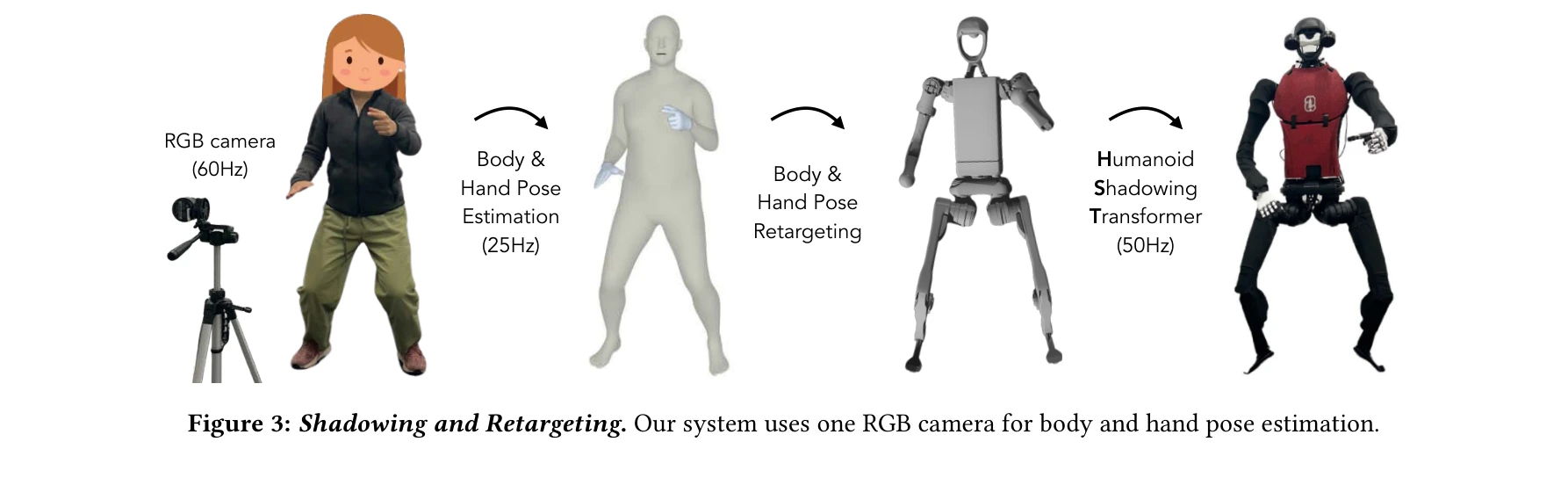
Figure 3: Shadowing and Retargeting. Our system uses one RGB camera for body and hand pose estimation.
휴머노이드 로봇이 단일 RGB 카메라를 사용하여 인간의 동작을 실시간으로 따라할 수 있는 shadowing 시스템과, 수집된 데이터로부터 자율적인 작업 기술을 학습하는 imitation learning 파이프라인을 제시하는 전체 스택 시스템이다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 휴머노이드 로봇의 인간 데이터 활용이라는 오랫동안의 과제에 대해 실용적이고 완성도 높은 end-to-end 시스템을 제시했으며, RGB 카메라 기반 shadowing의 단순성과 효율성, 그리고 다양한 자율 작업의 성공적 구현은 로봇 공학 분야에 실질적인 기여를 한다.
