저자: Huayi Wang, Wentao Zhang, Runyi Yu, Tao Huang, Junli Ren, Feiyu Jia, Zirui Wang, Xiaojie Niu, Xiao Chen, Jiahe Chen, Qifeng Chen, Jingbo Wang, Jiangmiao Pang | 날짜: 2025-10-13 | DOI: 10.48550/arXiv.2510.11072 📄 PDF
Essence
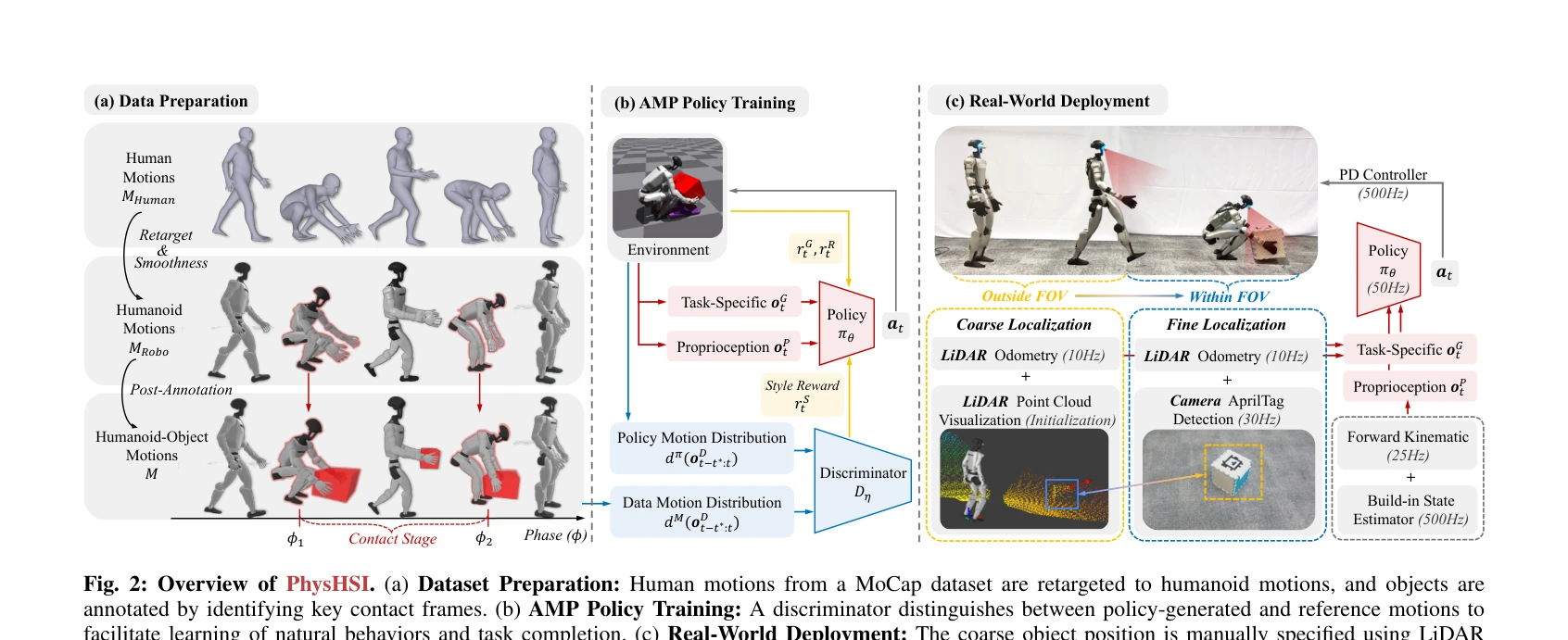
Fig. 2: Overview of PhysHSI. (a) Dataset Preparation: Human motions from a MoCap dataset are retargeted to humanoid moti
PhysHSI는 humanoid 로봇이 실제 환경에서 물체 운반, 앉기, 누우기 등 다양한 상호작용을 자연스럽고 일반화 가능하게 수행할 수 있도록 하는 통합 시스템으로, simulation 기반 AMP 정책 학습과 실시간 LiDAR-camera 기반 객체 인식 모듈을 결합한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: PhysHSI는 AMP 기반 motion learning과 hybrid sensor fusion을 통합하여 humanoid의 실세계 scene interaction을 처음 실현한 high-impact system으로, 자연스러운 동작과 robust generalization을 동시에 달성했으나, annotation 자동화와 marker-free perception 확대가 실용 배포의 과제이다.
