저자: Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, Chengkai Hou, Mengdi Zhao, KC alex Zhou, Pheng-Ann Heng, Shanghang Zhang | 날짜: 2025-03-13 | URL: https://arxiv.org/abs/2503.10631 📄 PDF
Essence
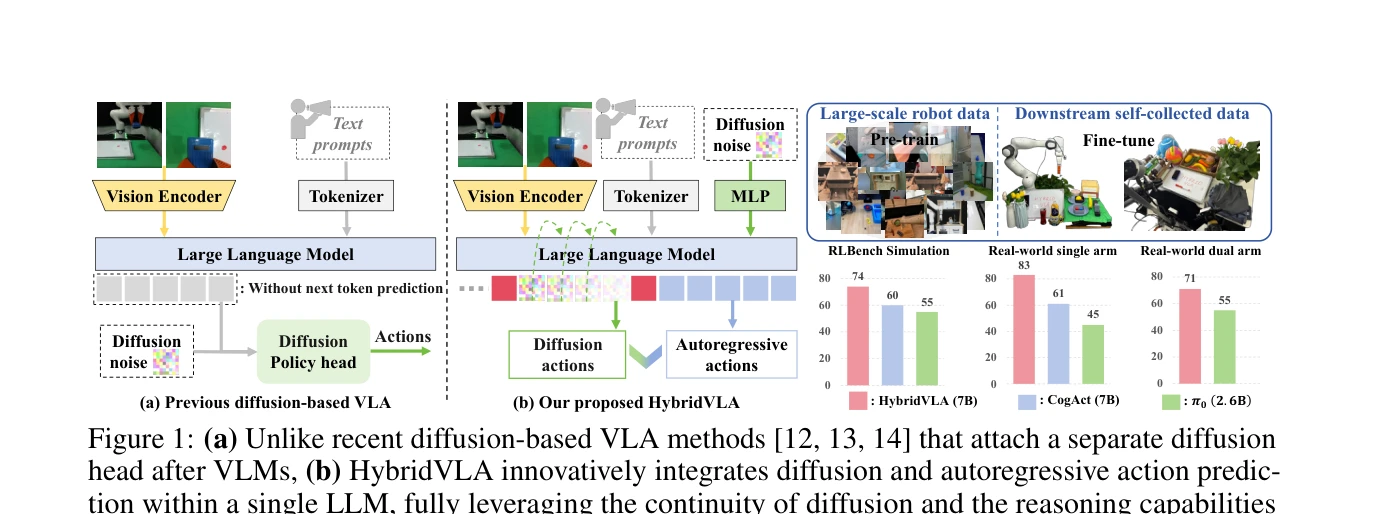
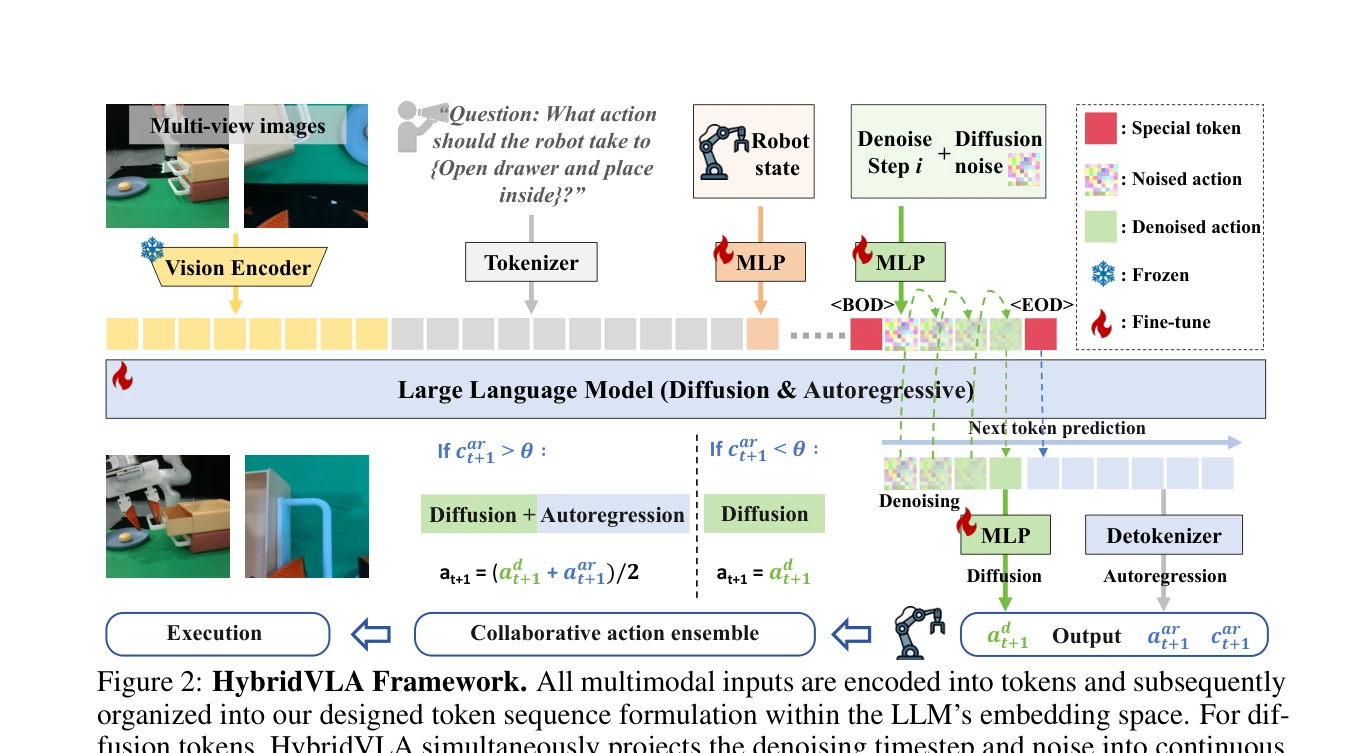
Figure 1: (a) Unlike recent diffusion-based VLA methods [12, 13, 14] that attach a separate diffusion
HybridVLA는 diffusion 기반 action 예측의 연속성과 autoregressive VLM의 추론 능력을 단일 LLM 내에서 통합하는 unified vision-language-action 모델이다. Collaborative training recipe와 adaptive action ensemble mechanism을 통해 두 생성 패러다임의 상호 강화를 실현한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: HybridVLA는 diffusion과 autoregressive 기반 action 생성의 근본적 한계를 unified architecture와 collaborative training을 통해 우아하게 해결하며, 광범위한 실험과 state-of-the-art 성과를 통해 로봇 조작 분야에 실질적인 진전을 제시하는 견고한 논문이다.