저자: Junhao Cai, Zetao Cai, Jiafei Cao, Yilun Chen, Zeyu He, Lei Jiang, Hang Li, Hengjie Li, Yang Li, Yufei Liu, Yanan Lu, Qi Lv, Haoxiang Ma, Jiangmiao Pang, Yu Qiao, Zherui Qiu, Yanqing Shen, Xu Shi, Yang Tian, Bolun Wang, Hanqing Wang, Jiaheng Wang, Tai Wang, Xueyuan Wei, Chao Wu, Yiman Xie, Boyang Xing, Yuqiang Yang, Yuyin Yang, Qiaojun Yu, Feng Yuan, Jia Zeng, Jingjing Zhang, Shenghan Zhang, Shi Zhang, Zhuoma Zhaxi, Bowen Zhou, Yuanzhen Zhou, Yunsong Zhou, Hongrui Zhu, Yangkun Zhu, Yuchen Zhu | 날짜: 2026-01-05 | URL: https://arxiv.org/abs/2601.02456 📄 PDF
Essence
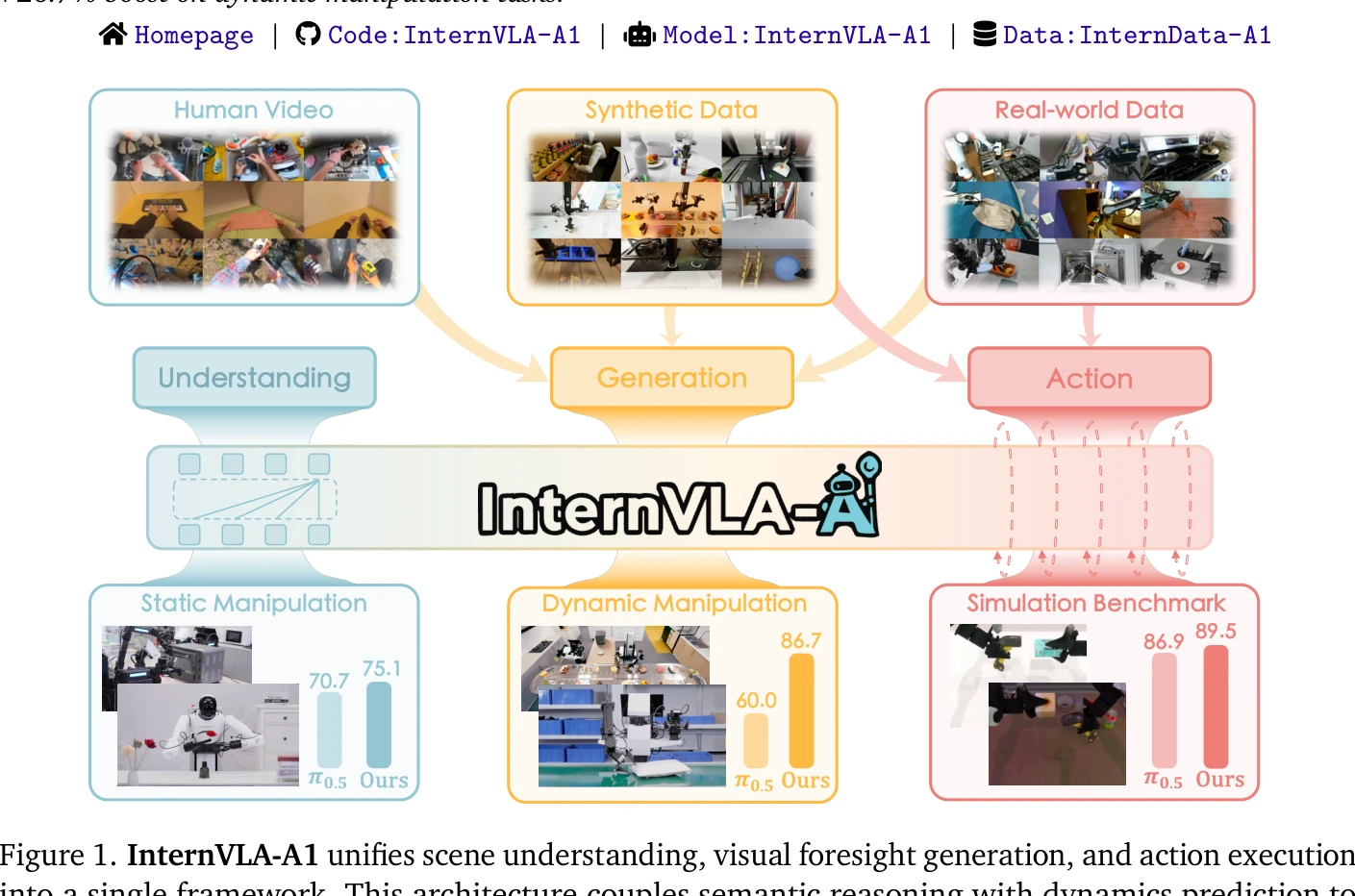
Figure 1. InternVLA-A1 unifies scene understanding, visual foresight generation, and action execution
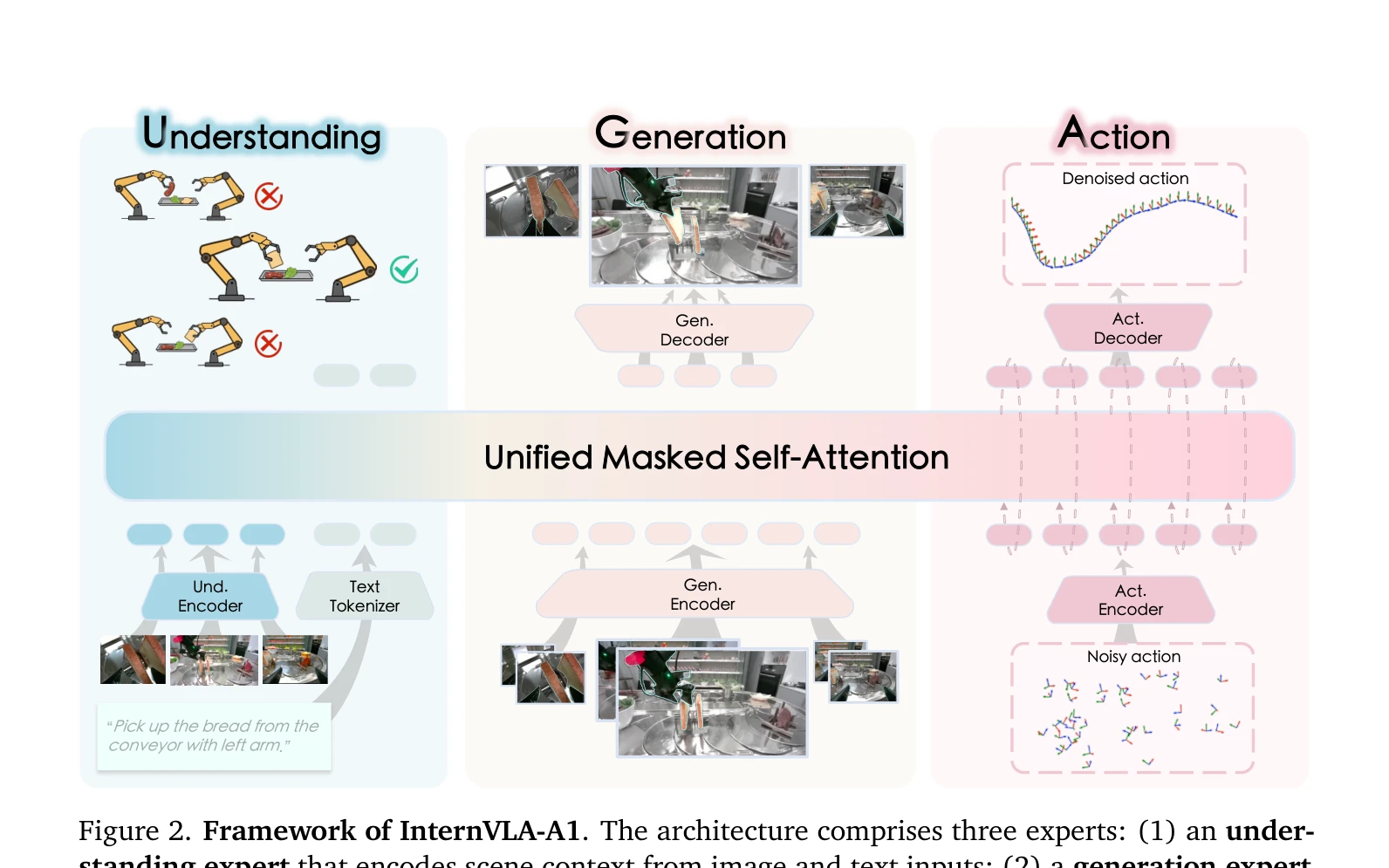
InternVLA-A1은 Mixture-of-Transformers 아키텍처를 통해 의미 이해, 시각적 예측, 행동 실행을 통합하여 로봇 조작 성능을 향상시키는 Vision-Language-Action 모델이다. 실세계 로봇 데이터, 합성 시뮬레이션 데이터, 인간 비디오를 포함한 692M 프레임의 이질적 데이터로 사전학습되어 동적 조작 작업에서 26.7% 성능 향상을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: InternVLA-A1은 의미 이해와 동적 예측을 통합하는 혁신적 아키텍처와 이질적 데이터 source의 효과적 활용으로 로봇 조작의 일반화 문제를 크게 향상시켰다. 특히 동적 환경에서의 26.7% 성능 향상은 실세계 응용의 중요한 진전을 보여주며, VLA 분야의 주요 기여이다.