Essence
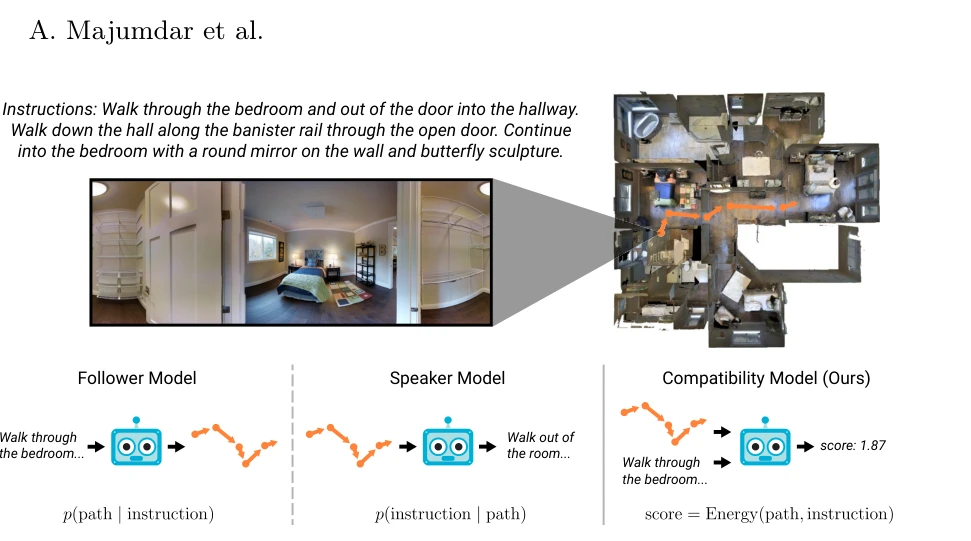
Fig. 1. We propose a compatibility model (right) for path selection in vision-and-
웹에서 수집한 대규모 이미지-텍스트 쌍으로 사전학습한 VLN-BERT 모델을 제안하여, 시각-언어 네비게이션 작업에서 객체 참조의 시각적 기초(grounding)를 개선한다.
저자: Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh, Dhruv Batra | 날짜: 2020-04-30 | URL: https://arxiv.org/abs/2004.14973 📄 PDF
Fig. 1. We propose a compatibility model (right) for path selection in vision-and-
웹에서 수집한 대규모 이미지-텍스트 쌍으로 사전학습한 VLN-BERT 모델을 제안하여, 시각-언어 네비게이션 작업에서 객체 참조의 시각적 기초(grounding)를 개선한다.

Fig. 2. Images from the Conceptual Captions (CC) [24] (top) and Matterport3D
총평: 웹 규모의 비정체화된 시각-언어 데이터를 embodied 네비게이션에 효과적으로 활용하는 실질적인 방법을 제안하며, 명확한 성능 개선과 체계적인 ablation study를 통해 학습 커리큘럼의 가치를 입증한 견고한 연구이다.