저자: Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Ming-Yu Liu, Donglai Xiang, Gordon Wetzstein, Tsung-Yi Lin | 날짜: 2025-03-27 | URL: https://arxiv.org/abs/2503.22020 📄 PDF
Essence
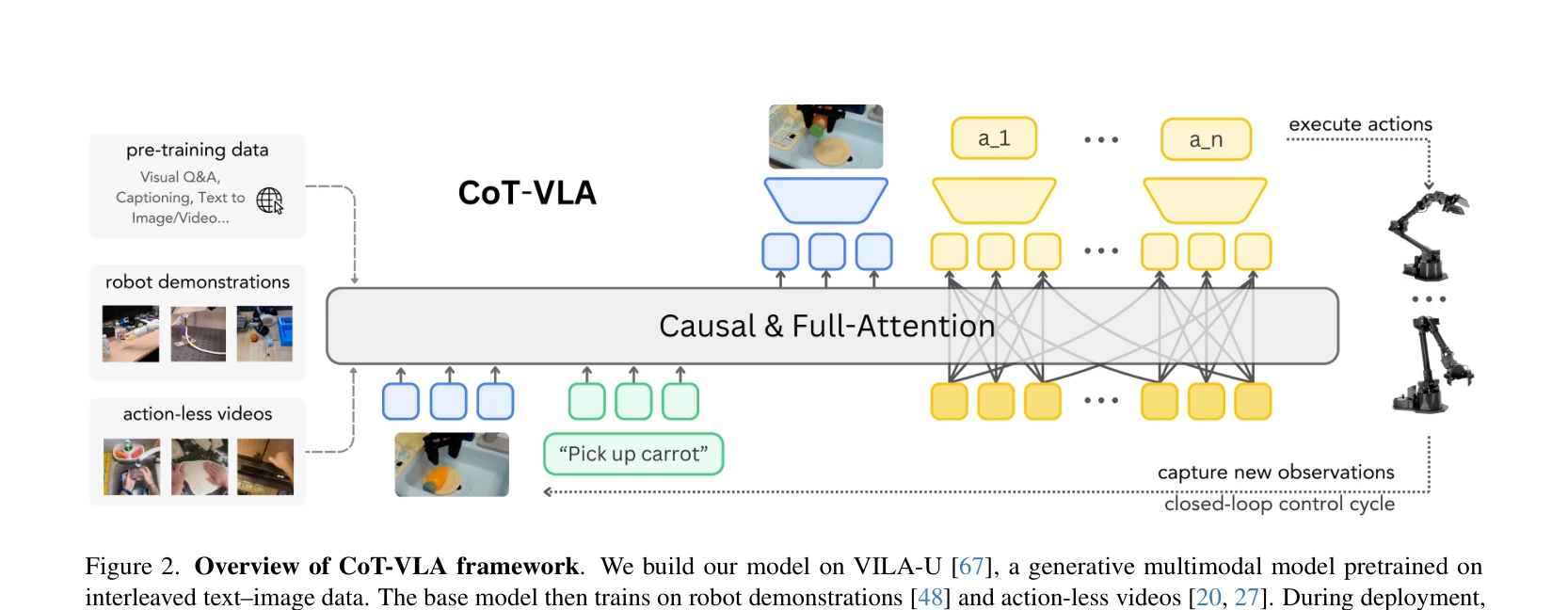
Figure 2. Overview of CoT-VLA framework. We build our model on VILA-U [67], a generative multimodal model pretrained on
이 논문은 Vision-Language-Action(VLA) 모델에 시각적 chain-of-thought 추론을 도입하여, 로봇이 직접 행동을 생성하기 전에 미래의 부분 목표 이미지를 자동회귀적으로 생성하도록 함으로써 로봇 조작 성능을 향상시킨다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 이 논문은 VLA에 visual chain-of-thought 추론을 도입하여 해석성과 성능을 동시에 개선한 혁신적인 작업이며, 행동 주석이 없는 비디오 데이터 활용이라는 실용적 이점과 함께 다양한 실험으로 효과성을 충분히 입증하였다.