저자: Jinzhou Lin, Han Gao, Xuxiang Feng, Rongtao Xu, Changwei Wang, Man Zhang, Li Guo, Shibiao Xu | 날짜: 2023-11-01 | URL: https://arxiv.org/abs/2311.00530 📄 PDF
Essence
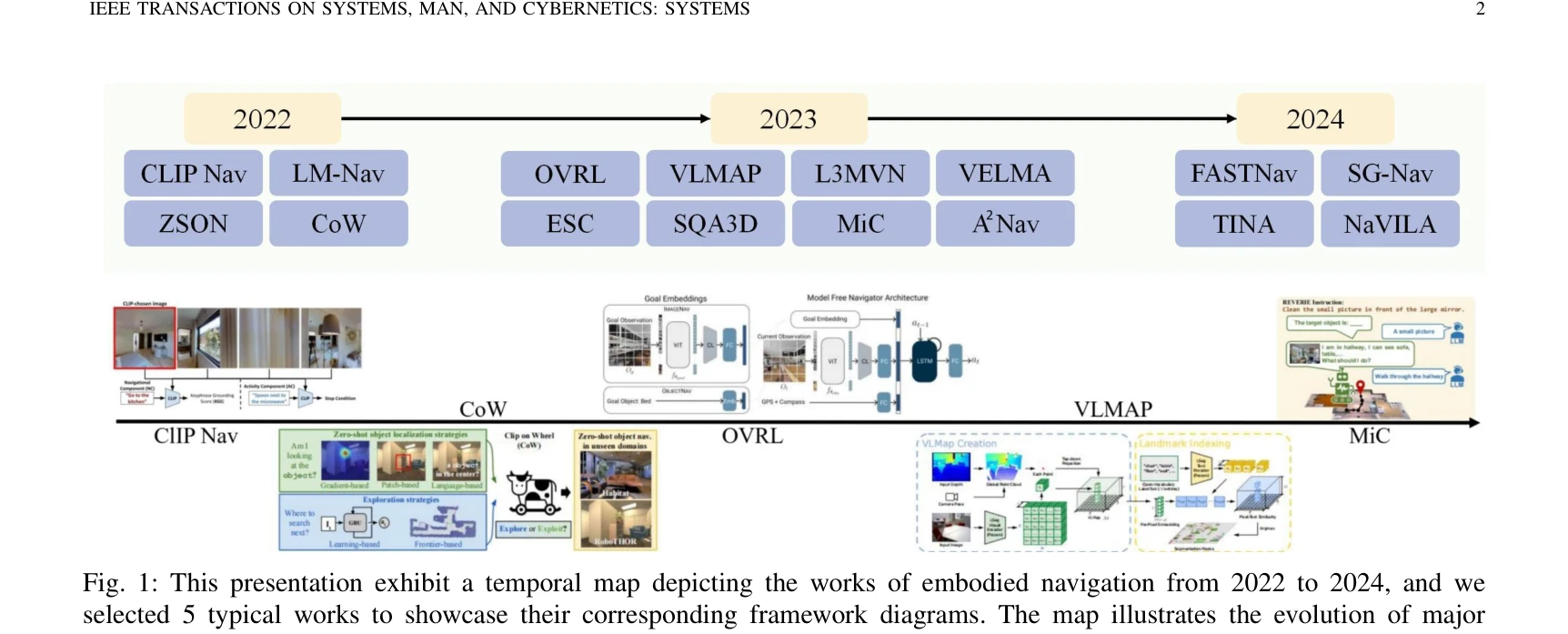
Fig. 1: This presentation exhibit a temporal map depicting the works of embodied navigation from 2022 to 2024, and we
이 논문은 Large Language Models (LLMs)과 embodied intelligence의 융합에 초점을 맞춰 LLM 기반 navigation 모델들의 최신 동향을 종합적으로 조사하고, 기존 모델과 데이터셋의 장단점을 분석한 서베이이다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 이 논문은 빠르게 성장하는 LLM 기반 embodied navigation 분야에 대한 첫 번째 체계적 서베이로서, 현재까지의 연구 성과를 명확히 분류하고 미래 방향을 제시하는 중요한 기여를 한다. 다만, 기술적 깊이와 실제 구현상의 도전과제에 대한 더욱 구체적인 분석이 보강된다면 실무자들에게 더욱 유용한 자료가 될 것이다.