저자: Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever | 날짜: 2021-02-26 | URL: https://arxiv.org/abs/2103.00020 📄 PDF
Essence
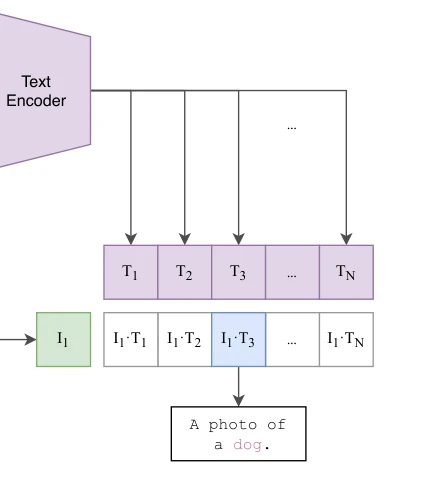
Figure 1. Summary of our approach. While standard image models jointly train an image feature extractor and a linear cla
400만 개의 (이미지, 텍스트) 쌍 데이터셋에서 이미지-텍스트 대조 학습(contrastive learning)을 통해 전이 가능한 시각 모델을 학습하고, 자연언어를 이용한 zero-shot 전이로 30개 이상의 다양한 컴퓨터 비전 작업에서 경쟁력 있는 성능을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: CLIP은 대규모 자연언어 지도학습을 통해 zero-shot 전이 성능의 새로운 기준을 제시하며, 간단한 contrastive 학습 목표의 확장성을 입증함으로써 다양한 비전 작업에 대한 범용 시각 모델의 가능성을 열었다.