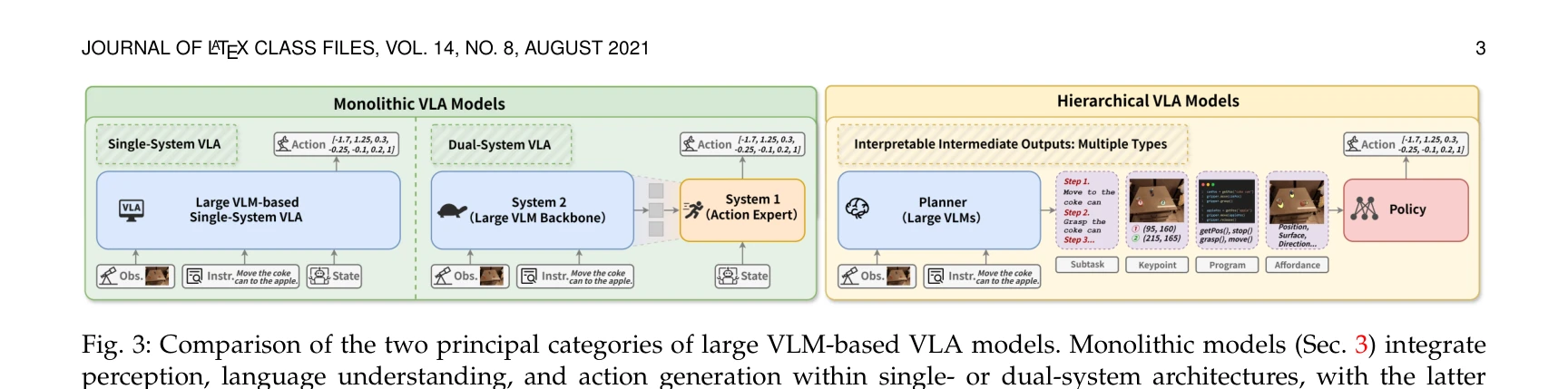
Essence
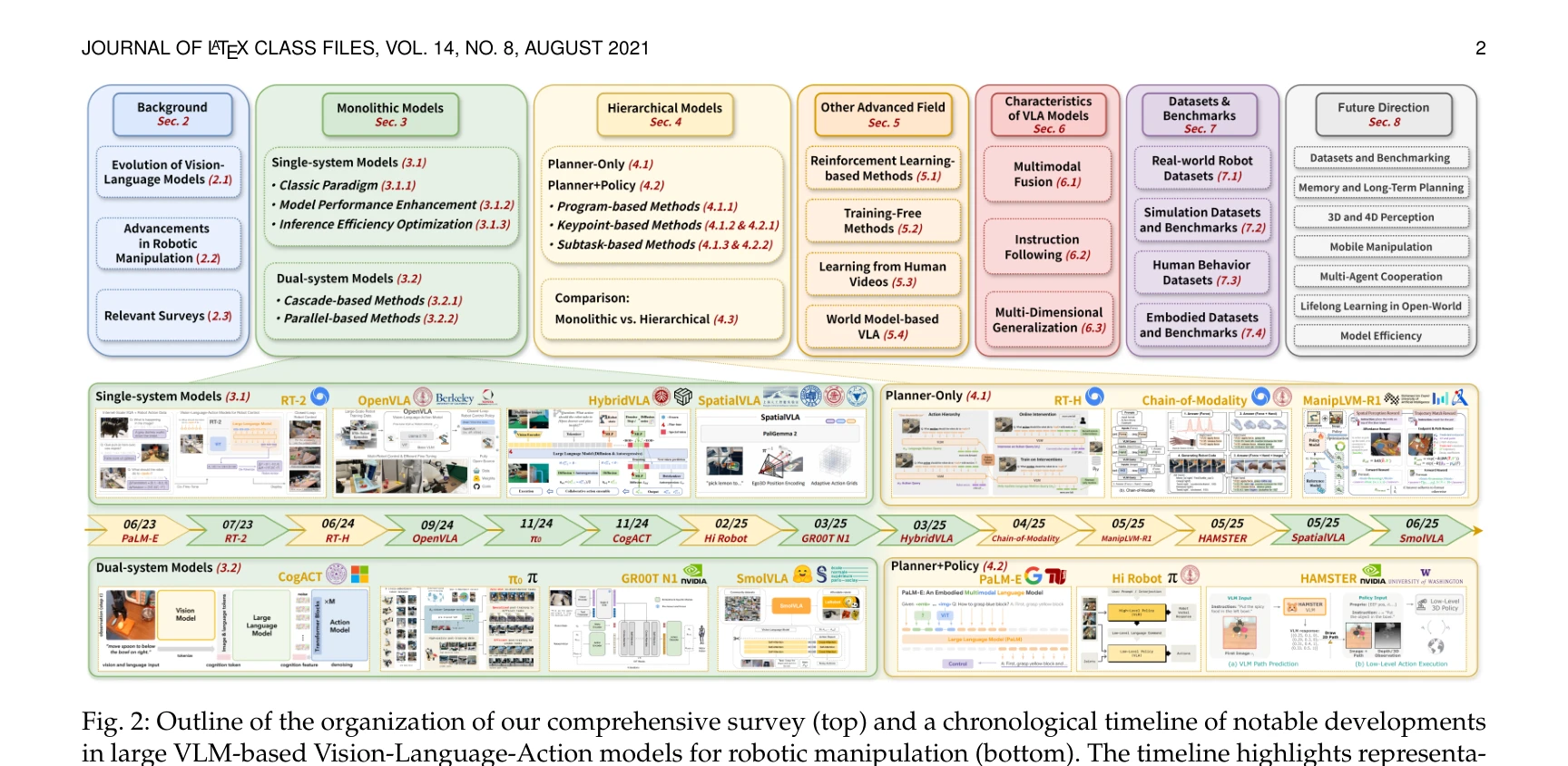
Fig. 2: Outline of the organization of our comprehensive survey (top) and a chronological timeline of notable developmen
대규모 Vision-Language Model(VLM)을 기반으로 한 Vision-Language-Action(VLA) 모델들을 로봇 매니퓰레이션에 적용하는 연구의 첫 번째 체계적 설문조사로, Monolithic 모델과 Hierarchical 모델이라는 두 가지 주요 아키텍처 패러다임을 제시한다.