저자: Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, Zhaoxiang Zhang | 날짜: 2025-06-24 | URL: https://arxiv.org/abs/2506.19850 📄 PDF
Essence
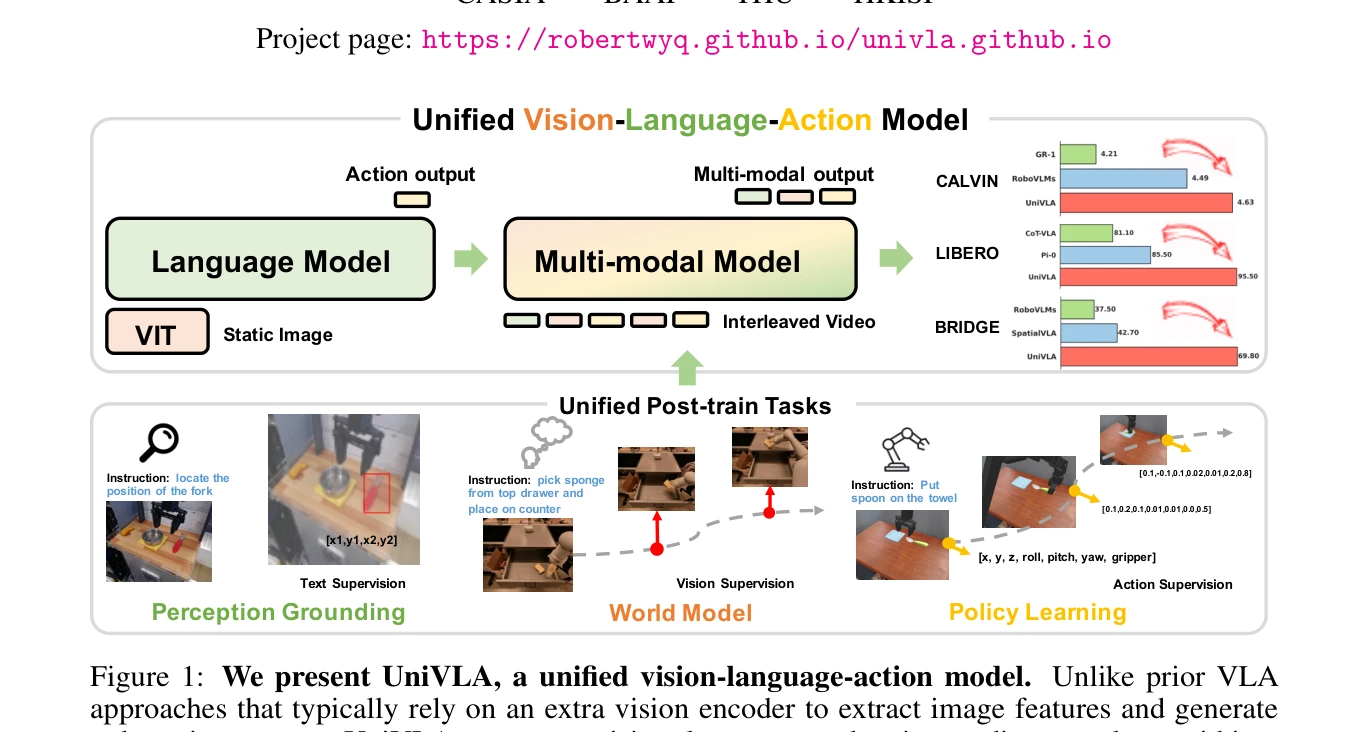
Figure 1: We present UniVLA, a unified vision-language-action model. Unlike prior VLA
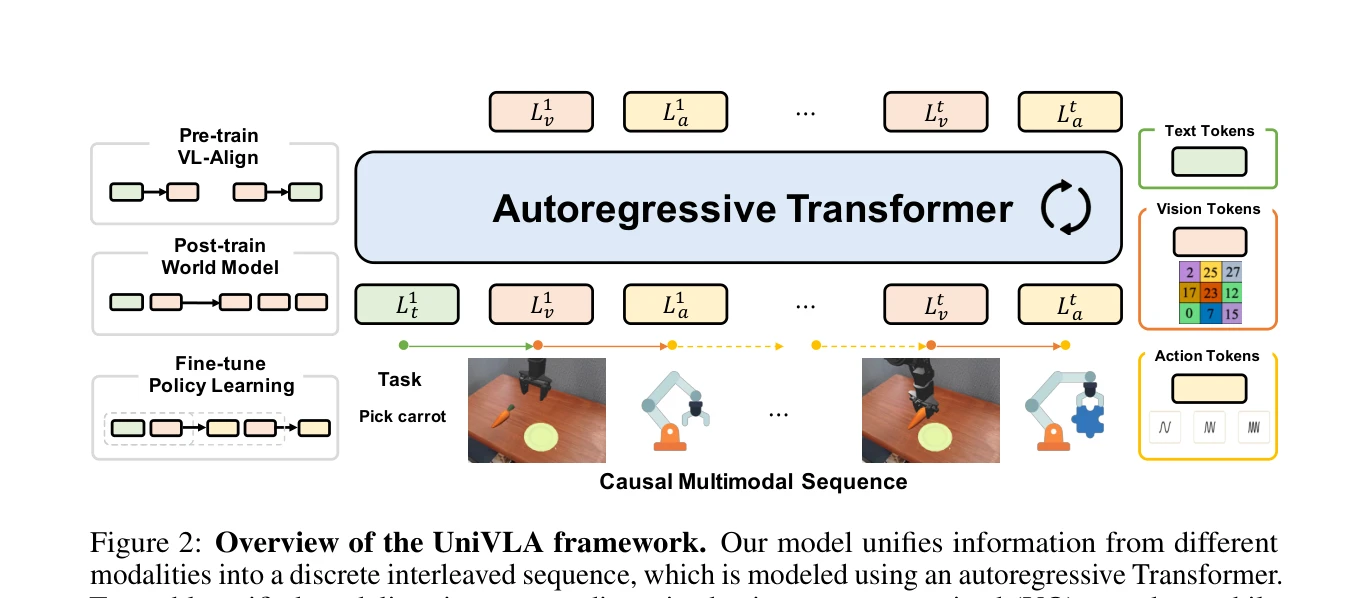
UniVLA는 vision, language, action을 discrete token으로 통일하여 autoregressive sequence modeling으로 joint하게 학습하는 unified vision-language-action model이다. World model을 post-training에 통합하여 비디오에서 temporal dynamics를 학습하고 downstream policy learning을 강화한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: UniVLA는 heterogeneous modalities를 unified discrete token 프레임워크로 통합하고 world model post-training으로 temporal dynamics를 학습하는 혁신적인 VLA 모델이다. 다중 벤치마크에서 SOTA 성능을 달성했으며, multimodal capability와 large-scale video training 가능성으로 generalist embodied AI의 새로운 방향을 제시한다.