Essence
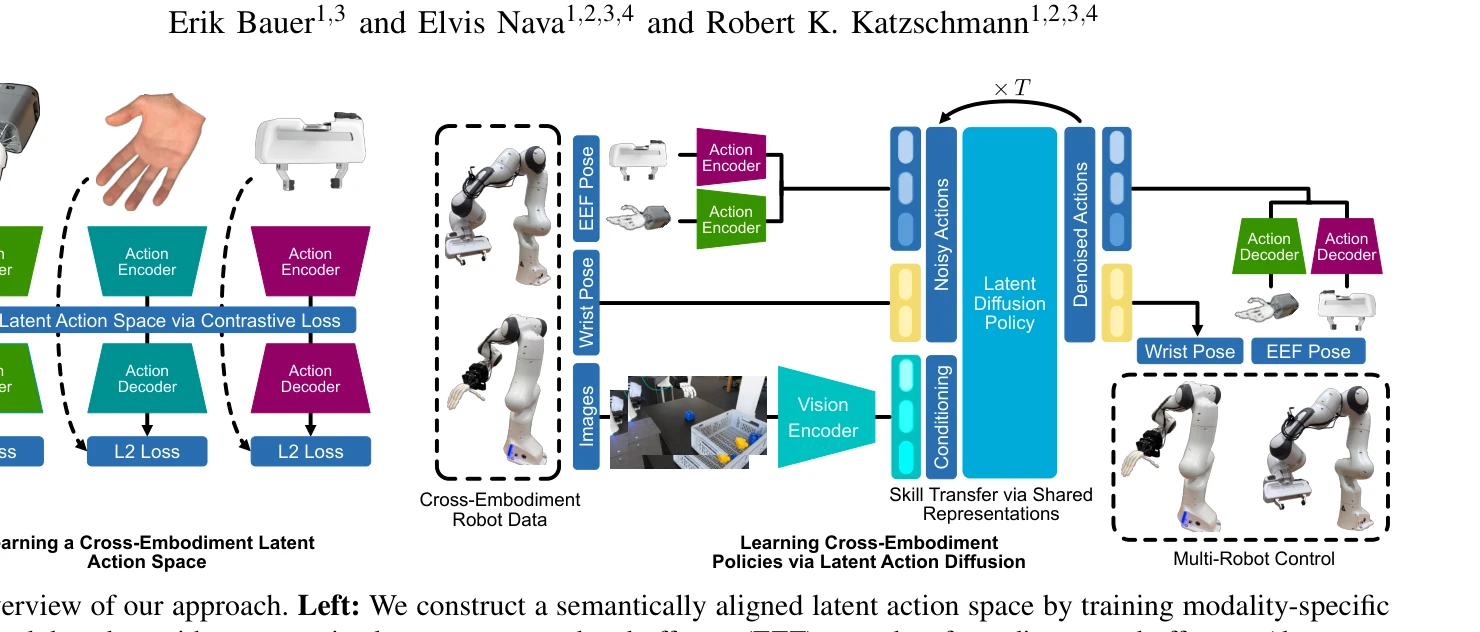
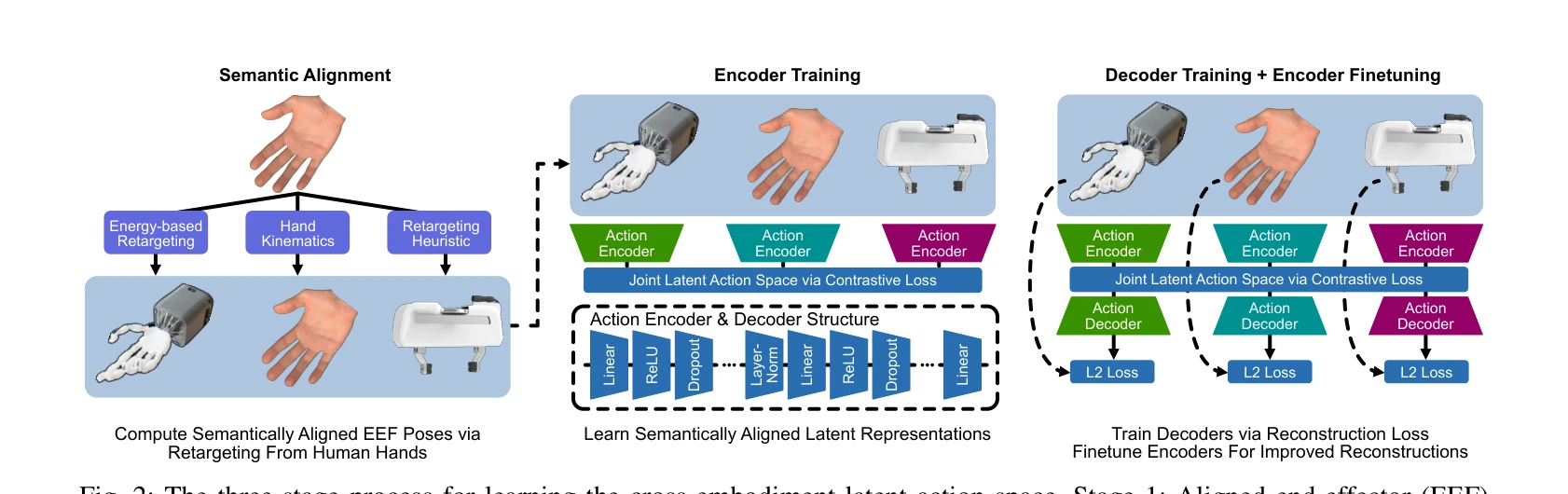
Fig. 1: Overview of our approach. Left: We construct a semantically aligned latent action space by training modality-spe
로봇의 다양한 end-effector 간 action space 이질성을 극복하기 위해 contrastive learning으로 학습된 shared latent action space에서 diffusion policy를 학습하여 cross-embodiment 조작을 실현한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
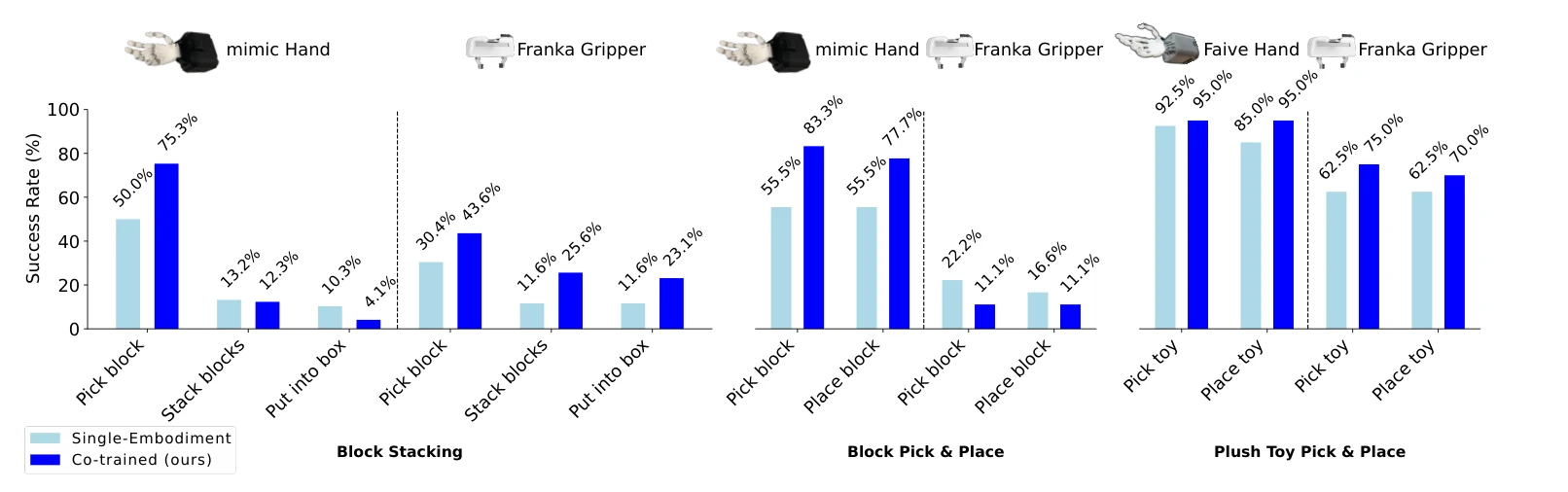
총평: Cross-embodiment 로봇 학습의 action space 이질성 문제를 learned latent representation으로 우아하게 해결하고, contrastive learning과 diffusion policy를 조합하여 실제 성능 향상을 입증한 가치있는 연구이다. 다만 embodiment 다양성 범위 확대와 alignment 메커니즘의 더 깊은 분석이 후속 과제이다.