저자: Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z. Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, Karan Dhabalia, Michael Equi, Quan Vuong, Jost Tobias Springenberg, Sergey Levine, Chelsea Finn, Danny Driess | 날짜: 2026-03-04 | URL: https://arxiv.org/abs/2603.03596 📄 PDF
Essence
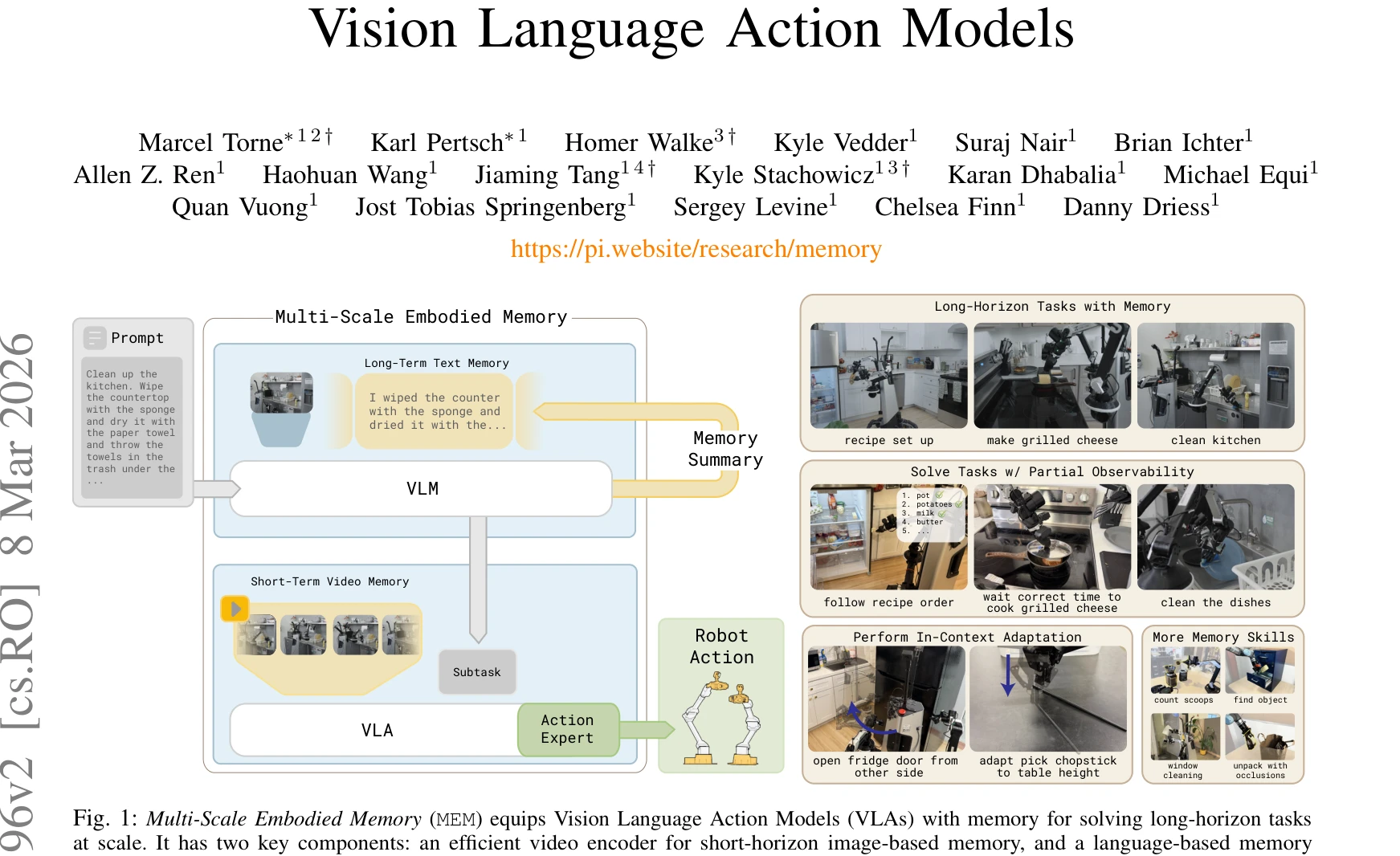
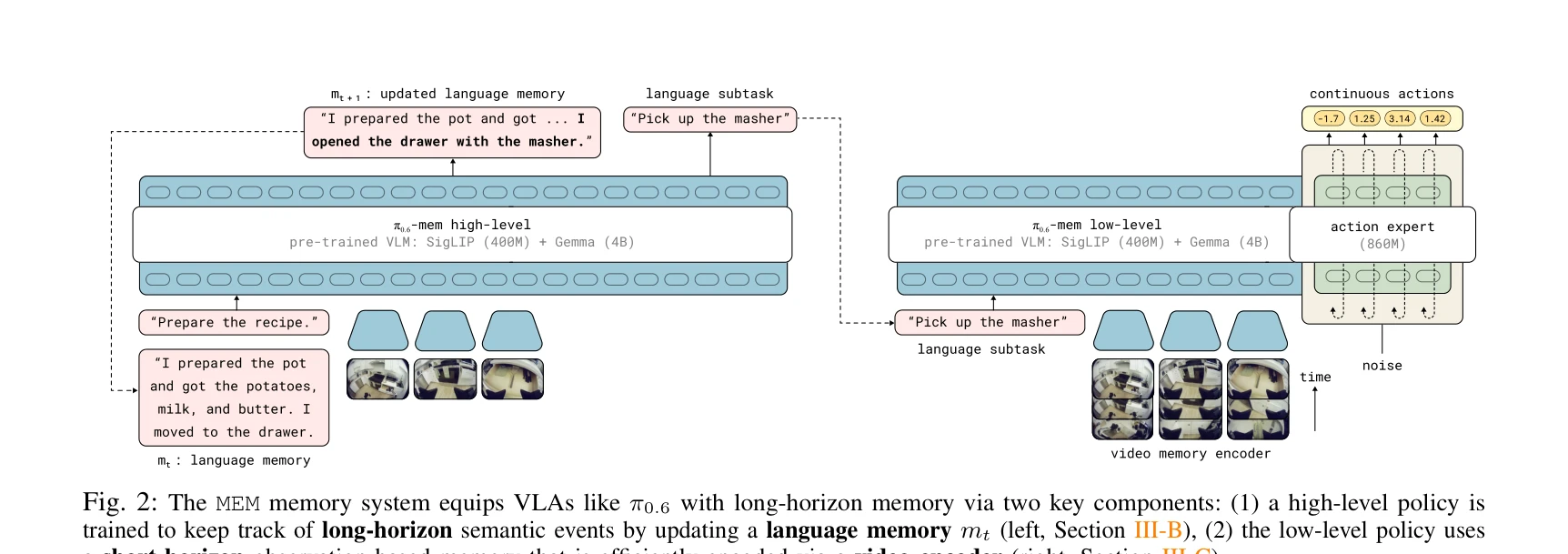
Fig. 1: Multi-Scale Embodied Memory (MEM) equips Vision Language Action Models (VLAs) with memory for solving long-horiz
로봇의 장시간 작업을 위해 비디오 기반 단기 메모리와 텍스트 기반 장기 메모리를 결합한 Multi-Scale Embodied Memory (MEM)을 제안하여, 15분 이상의 복잡한 조작 작업을 수행할 수 있는 Vision Language Action 모델을 구현했다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 로봇의 장시간 작업을 위한 다중 스케일 메모리 아키텍처를 창의적으로 제안하여 15분 이상의 복잡한 조작 작업을 처음으로 성공적으로 구현했으며, 이는 실제 로봇 자동화의 실용성을 크게 향상시키는 중요한 기여를 한다.