Essence

Figure 1: We introduce ThinkAct, a reasoning VLA framework capable of thinking before acting. Through
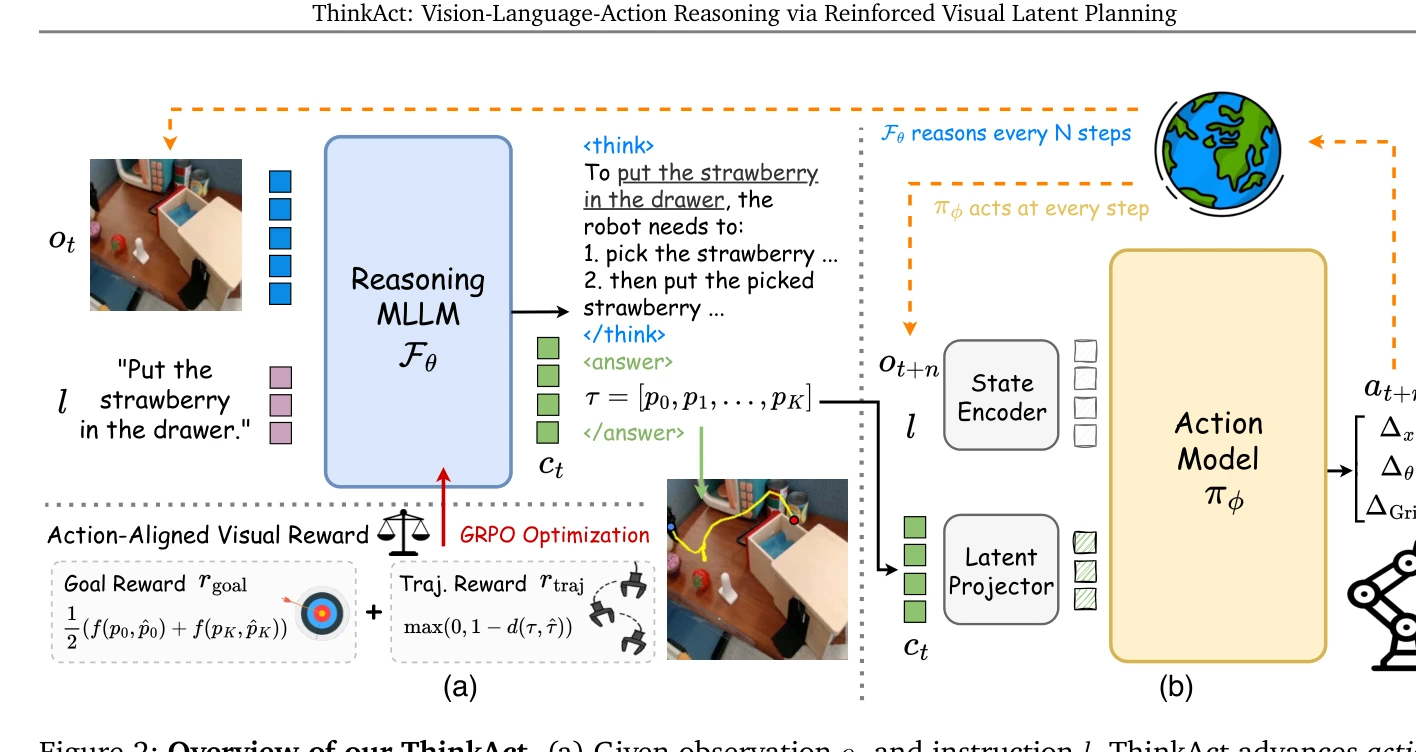
ThinkAct는 Vision-Language-Action 추론 작업을 위해 강화학습 기반 시각 잠재 계획을 통해 고수준 추론과 저수준 행동 실행을 연결하는 이중 시스템 프레임워크를 제안한다. 다중모달 LLM이 생성한 추론 계획을 시각 계획 잠재로 압축하여 다운스트림 행동 모델을 조건화하여 장기 계획, 소수샷 적응, 자체 수정 능력을 달성한다.