저자: Yi Chen, Yuying Ge, Weiliang Tang, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, Xihui Liu | 날짜: 2024-12-05 | URL: https://arxiv.org/abs/2412.04445 📄 PDF
Essence
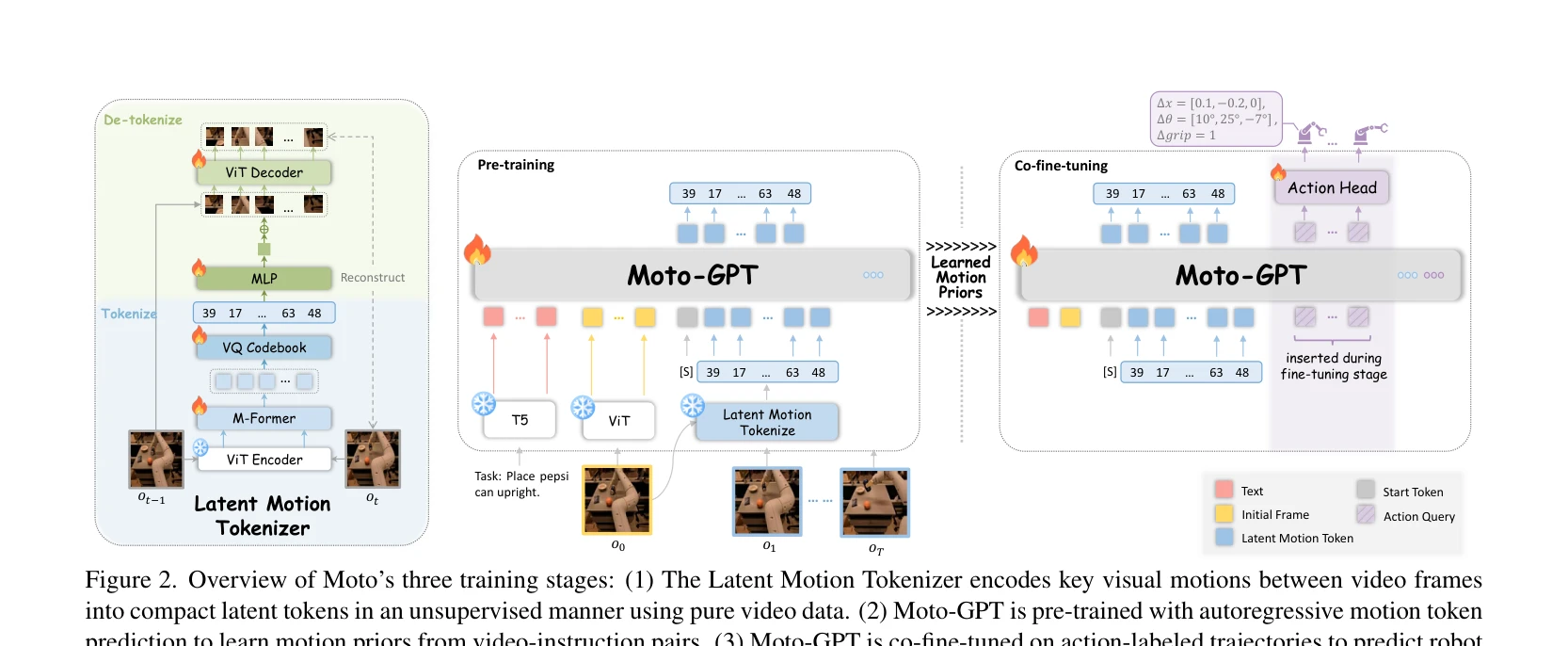
Figure 2. Overview of Moto’s three training stages: (1) The Latent Motion Tokenizer encodes key visual motions between v
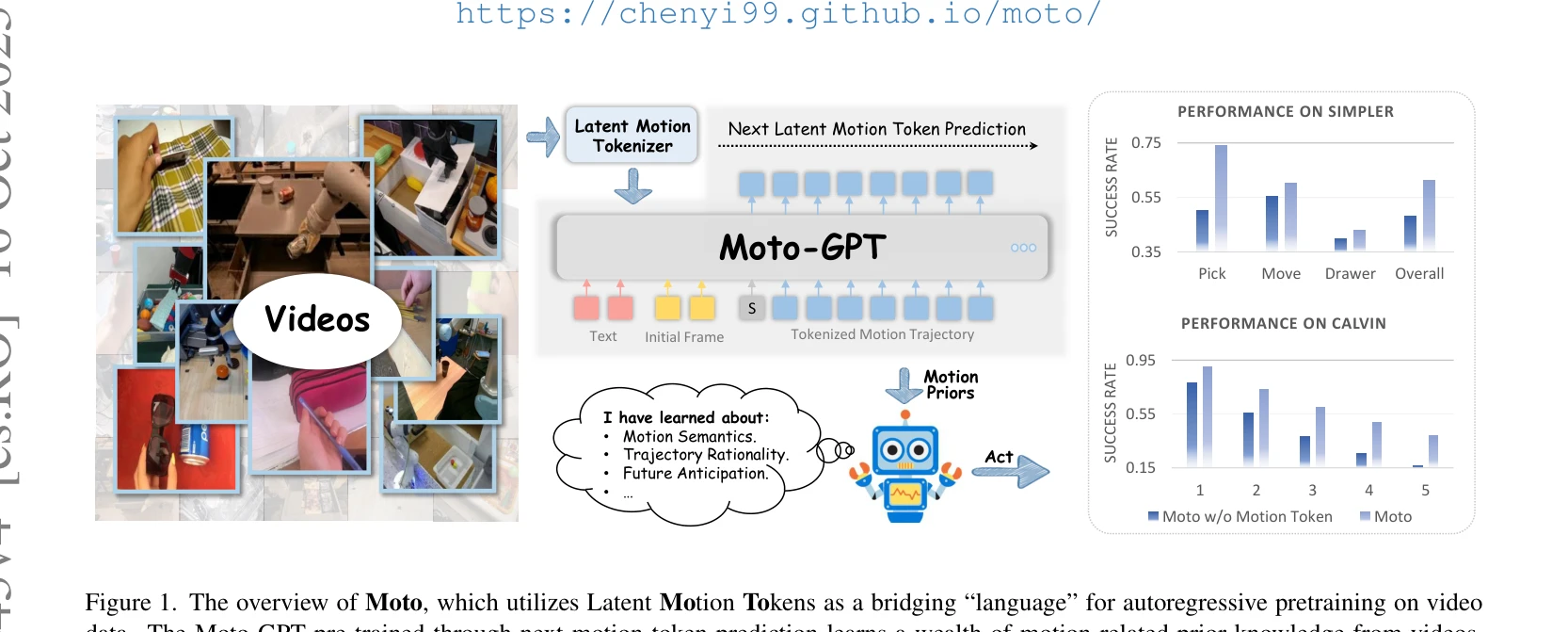
이 논문은 비디오에서 비지도 학습으로 latent motion token을 학습하여 로봇 조작 태스크를 위한 사전학습의 중간 표현으로 사용하고, Moto-GPT를 통해 motion token의 자동회귀 예측으로 motion prior를 학습한 후 co-fine-tuning으로 실제 로봇 제어로 전이하는 방법을 제안한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 이 논문은 latent motion token을 통해 비디오 사전학습과 로봇 제어를 우아하게 연결하는 창의적인 접근을 제시하며, motion prior의 학습과 전이에 대한 명확한 검증을 제공한다. 데이터 효율성과 해석 가능성 측면에서 로봇 학습에 의미 있는 기여를 하지만, 실제 로봇 환경에서의 광범위한 검증과 다양한 조작 복잡도에 대한 일반화 능력 증명이 필요하다.