Achievement

Figure 4: Autonomous rollouts of VITA on five challenging real-world tasks, including two bimanual
- 추론 속도 향상: 기존 conditioning 모듈 방식 대비 1.5×-2× 빠른 추론 속도 달성
- 메모리 효율성: 18.6%-28.7% 낮은 메모리 사용량으로 동일한 모델 크기에서 우수한 성능 구현
- 경쟁력 있는 성능: ALOHA와 Robomimic의 9개 시뮬레이션 및 5개 실제 작업에서 최첨단 정책과 동등하거나 우수한 성공률 달성
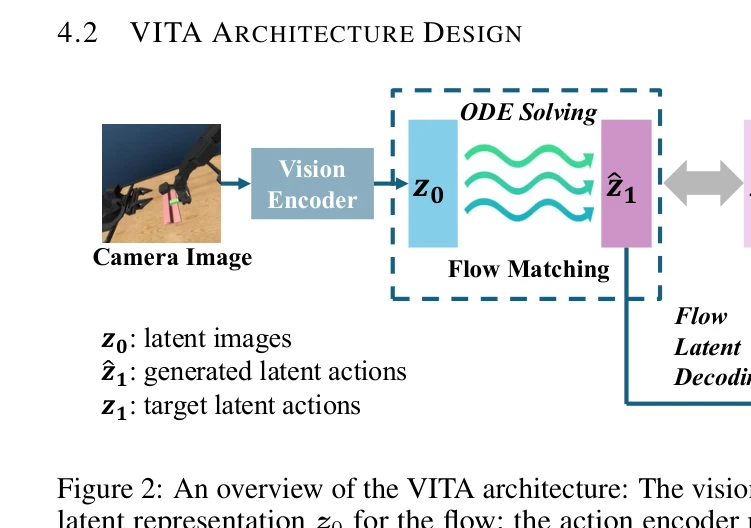
- 아키텍처 단순화: 첫 MLP-only flow matching 정책으로 ALOHA 이원 조작과 같이 도전적인 작업에 성공
- 학습 안정성: 빠른 수렴과 높은 정밀도를 유지하면서 안정적인 학습 달성