Essence
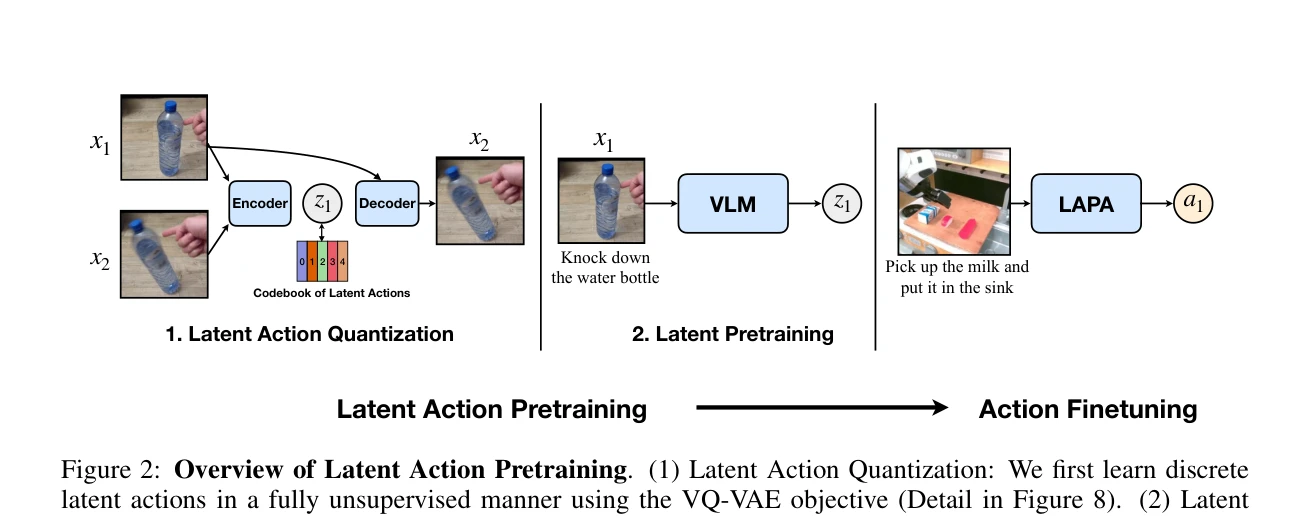
Figure 2: Overview of Latent Action Pretraining. (1) Latent Action Quantization: We first learn discrete
인터넷 규모의 라벨 없는 비디오에서 로봇 행동을 학습하기 위해 VQ-VAE 기반 잠재 행동 양자화와 Vision-Language-Action 모델 사전학습을 결합한 비지도 학습 방법을 제안한다.
저자: Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, Minjoon Seo | 날짜: 2024-10-15 | URL: https://arxiv.org/abs/2410.11758 📄 PDF
Figure 2: Overview of Latent Action Pretraining. (1) Latent Action Quantization: We first learn discrete
인터넷 규모의 라벨 없는 비디오에서 로봇 행동을 학습하기 위해 VQ-VAE 기반 잠재 행동 양자화와 Vision-Language-Action 모델 사전학습을 결합한 비지도 학습 방법을 제안한다.
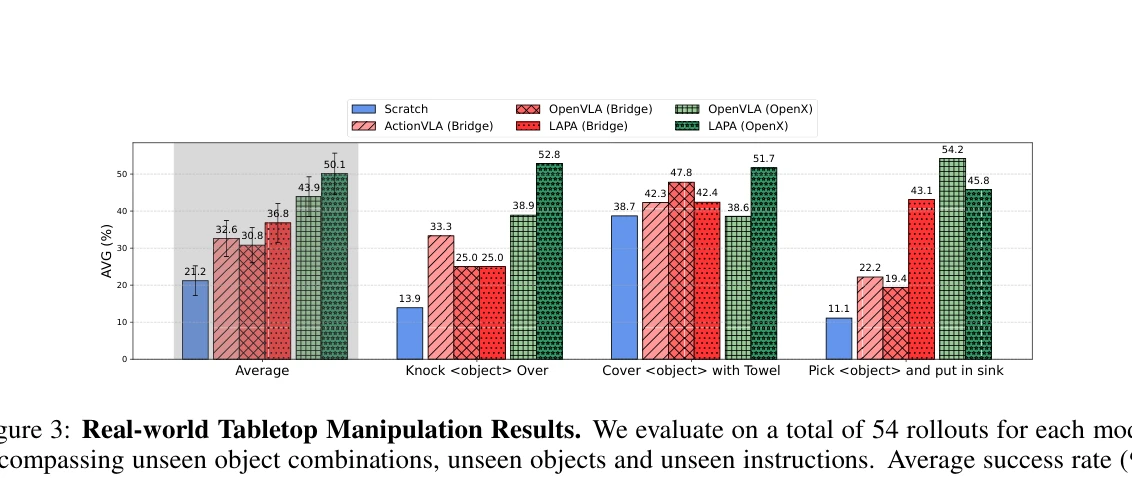
Figure 3: Real-world Tabletop Manipulation Results. We evaluate on a total of 54 rollouts for each model
Figure 2: Overview of Latent Action Pretraining. (1) Latent Action Quantization: We first learn discrete
총평: 로봇 학습의 주요 제약인 행동 레이블 의존성을 제거하는 혁신적 접근으로, 비지도 학습을 통해 인터넷 규모 데이터 활용을 가능하게 하며, 상태 기술 기술을 능가하는 실제 성능 향상을 입증한 매우 중요한 연구이다.