Essence

Figure 1: VOXPOSER extracts language-conditioned affordances and constraints from LLMs and grounds
LLM의 affordance 추론 능력과 code-writing 능력을 활용하여 3D value map을 생성하고, 이를 model-based planning으로 로봇 trajectory 합성에 활용하는 zero-shot 로봇 조작 방법론.
저자: Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, Li Fei-Fei | 날짜: 2023-07-12 | URL: https://arxiv.org/abs/2307.05973 📄 PDF
Figure 1: VOXPOSER extracts language-conditioned affordances and constraints from LLMs and grounds
LLM의 affordance 추론 능력과 code-writing 능력을 활용하여 3D value map을 생성하고, 이를 model-based planning으로 로봇 trajectory 합성에 활용하는 zero-shot 로봇 조작 방법론.

Figure 3: Visualization of composed 3D value maps and rollouts in real-world environments. The top row
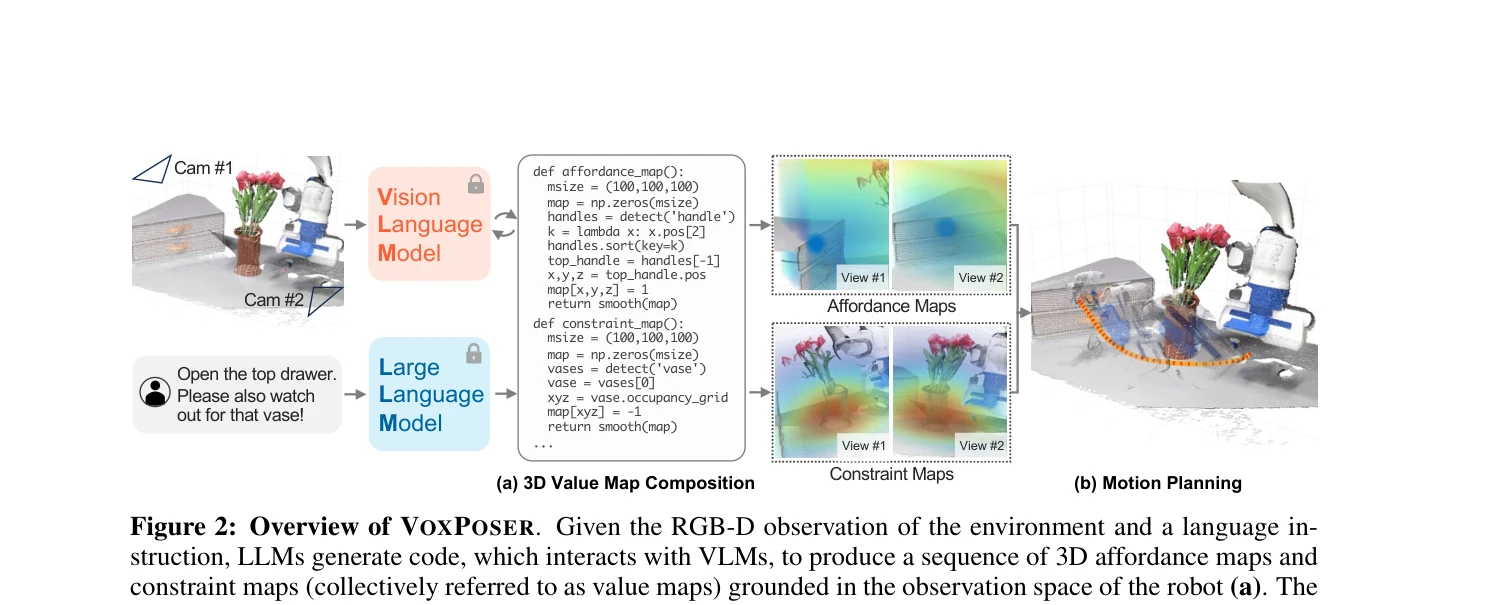
Figure 2: Overview of VOXPOSER. Given the RGB-D observation of the environment and a language in-
총평: VoxPoser는 LLM의 높은 수준 추론과 code 생성 능력을 3D 로봇 조작에 처음으로 효과적으로 연결한 혁신적 방법으로, zero-shot 일반화와 실제 로봇 적용 가능성을 보여주는 의미 있는 기여이다. 다만 affordance 정확성, 장기 계획, 계산 효율성 측면의 개선이 필요하다.