Essence
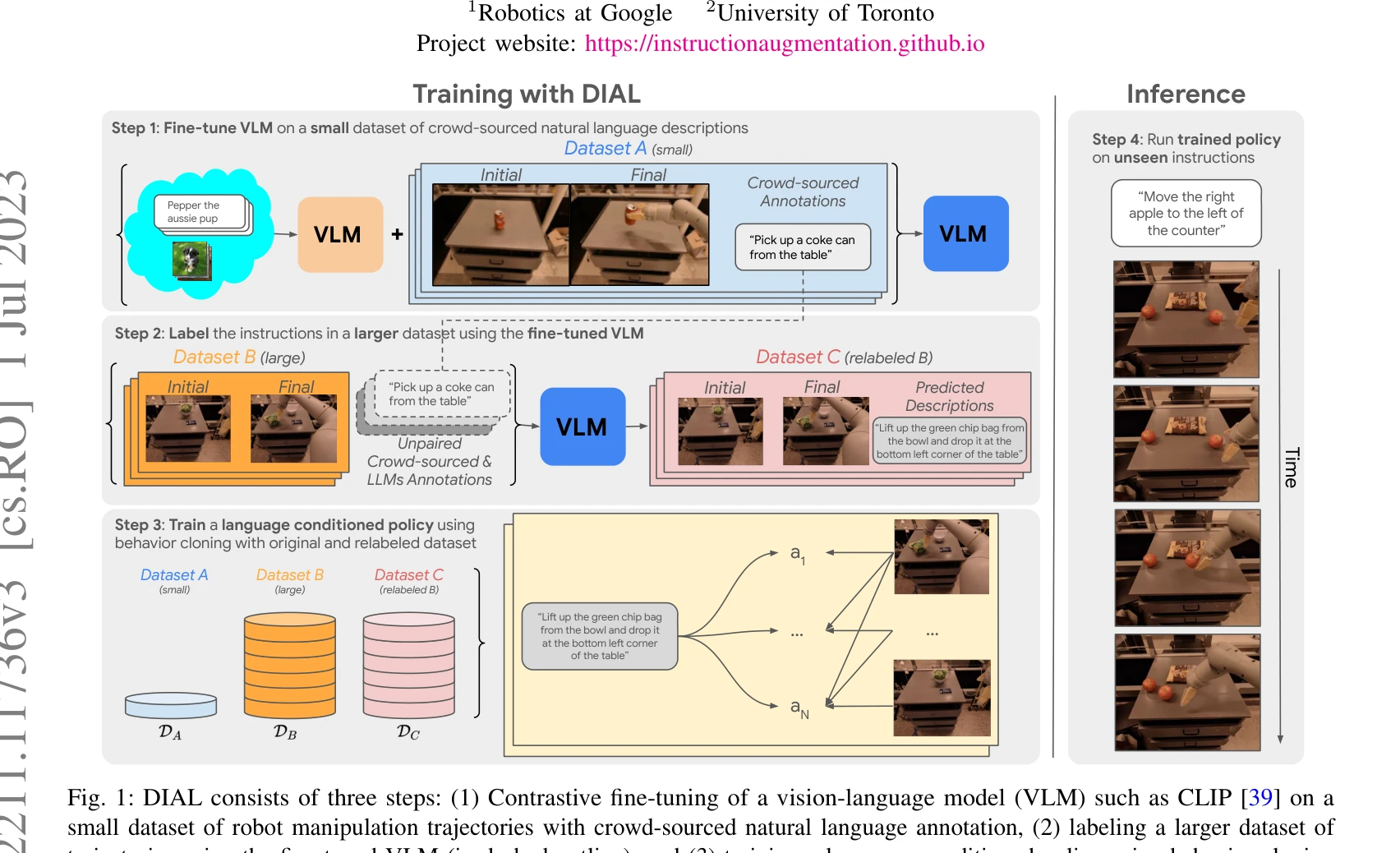
Fig. 1: DIAL consists of three steps: (1) Contrastive fine-tuning of a vision-language model (VLM) such as CLIP [39] on
Vision-Language Model (CLIP)을 미세조정하여 주석이 없는 대규모 로봇 조작 데이터셋에 자동으로 자연어 명령어를 생성하고, 이를 통해 언어 조건부 정책을 학습하는 DIAL 방법을 제안한다.
저자: Ted Xiao, Harris Chan, Pierre Sermanet, Ayzaan Wahid, Anthony Brohan, Karol Hausman, Sergey Levine, Jonathan Tompson | 날짜: 2022-11-21 | URL: https://arxiv.org/abs/2211.11736 📄 PDF
Fig. 1: DIAL consists of three steps: (1) Contrastive fine-tuning of a vision-language model (VLM) such as CLIP [39] on
Vision-Language Model (CLIP)을 미세조정하여 주석이 없는 대규모 로봇 조작 데이터셋에 자동으로 자연어 명령어를 생성하고, 이를 통해 언어 조건부 정책을 학습하는 DIAL 방법을 제안한다.

Fig. 5: Given the same starting scene, DIAL follows the instructions of (a) pick can which is on the right of
Fig. 1: DIAL consists of three steps: (1) Contrastive fine-tuning of a vision-language model (VLM) such as CLIP [39] on
총평: VLM을 데이터 주석 도구로 활용하는 실용적이고 확장 가능한 방법을 제시하며, 1,300회 이상의 실제 로봇 평가를 통해 효과를 입증했다. 로봇 학습의 비용 효율성을 크게 향상시킬 수 있는 가치 있는 기여이다.