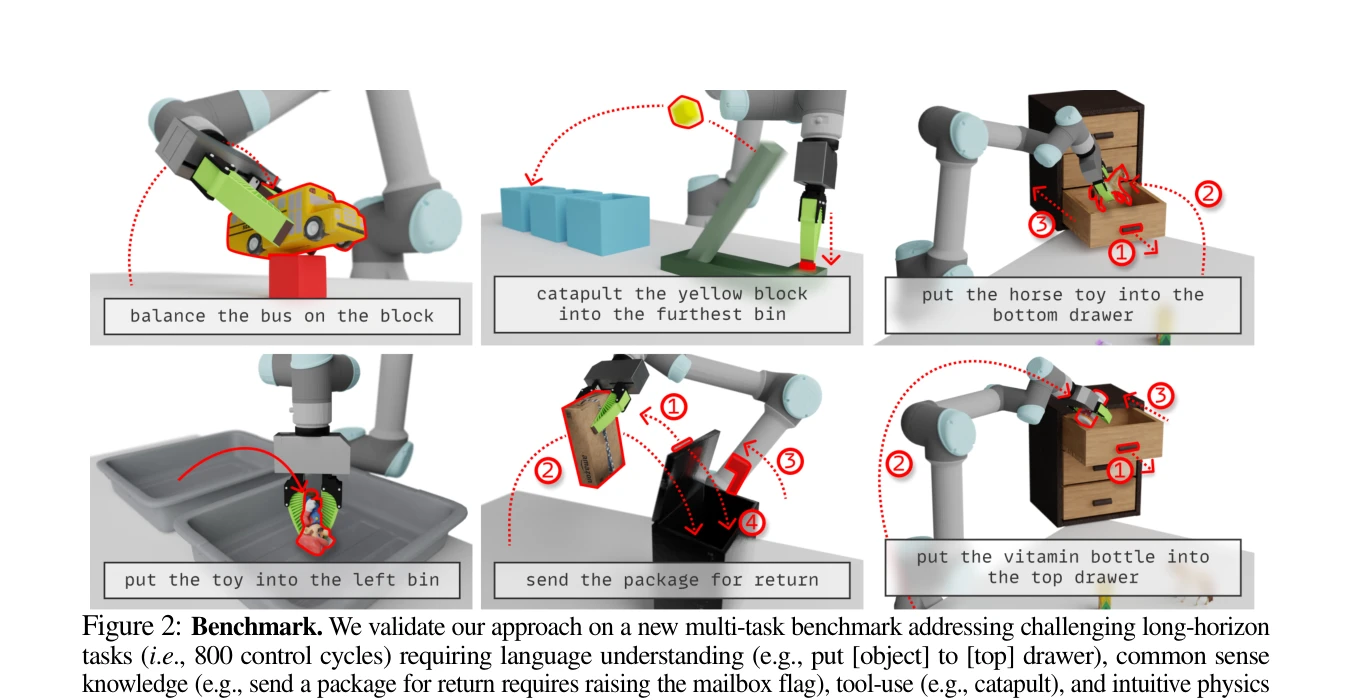
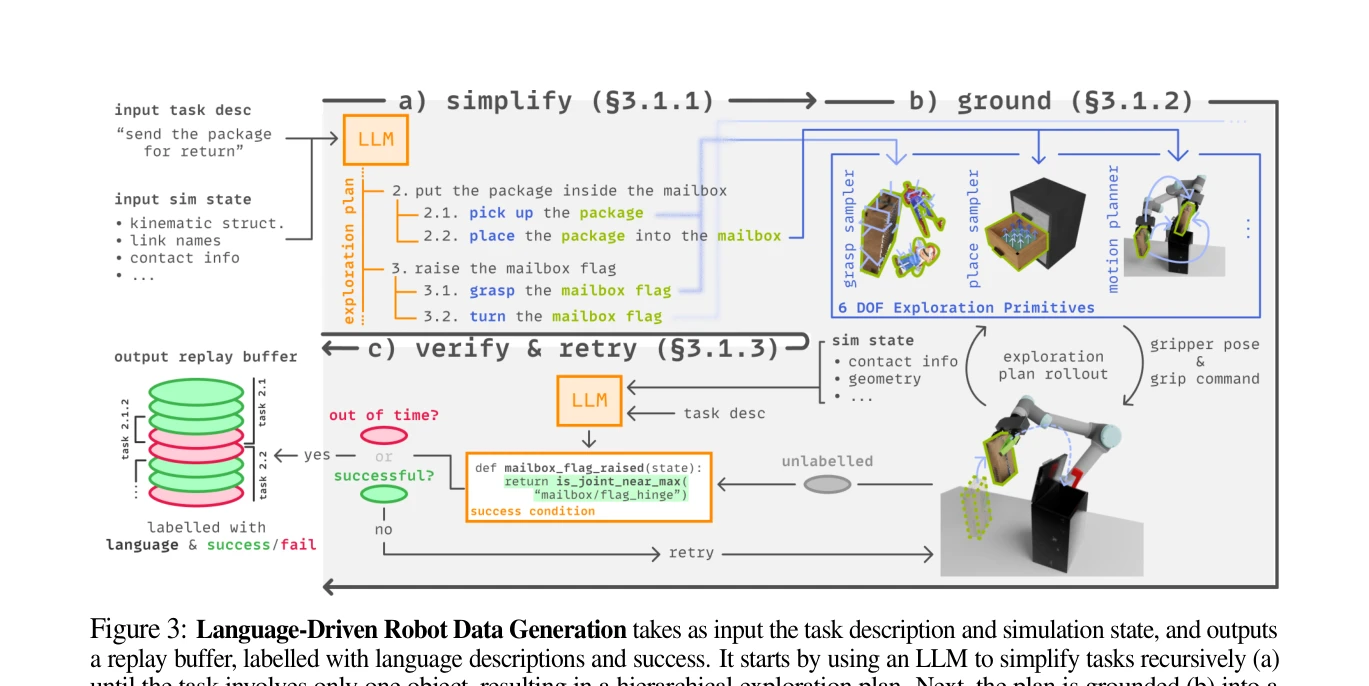
Essence
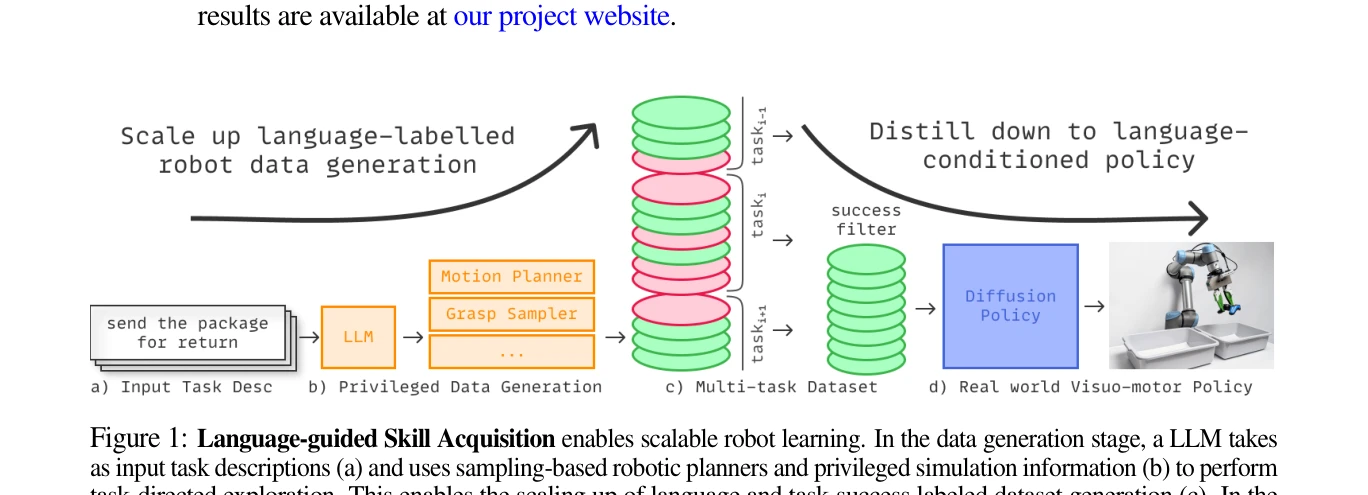
Figure 1: Language-guided Skill Acquisition enables scalable robot learning. In the data generation stage, a LLM takes
LLM 기반 고수준 계획과 sampling-based robot planner를 활용하여 언어-레이블 로봇 데이터 생성을 확장하고, 이를 diffusion policy를 통해 다중 작업 언어-조건 visuo-motor 정책으로 증류하는 로봇 스킬 획득 프레임워크를 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM 기반 계획과 sampling-based planning을 결합한 자동 로봇 데이터 생성과 multi-task diffusion policy 학습의 novel한 통합 프레임워크를 제시하며, 33.2% 성능 향상과 함께 로봇 스킬 습득의 확장 가능성을 입증한다. 다중 작업 벤치마크와 함께 로봇 학습 분야에 의미 있는 기여를 하고 있다.