저자: Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqiang Yang, Delin Feng, Wenzhe Cai, Chenming Zhu, Tai Wang, Jiangmiao Pang, Xihui Liu | 날짜: 2025-12-09 | URL: https://arxiv.org/abs/2512.08186 📄 PDF
Essence
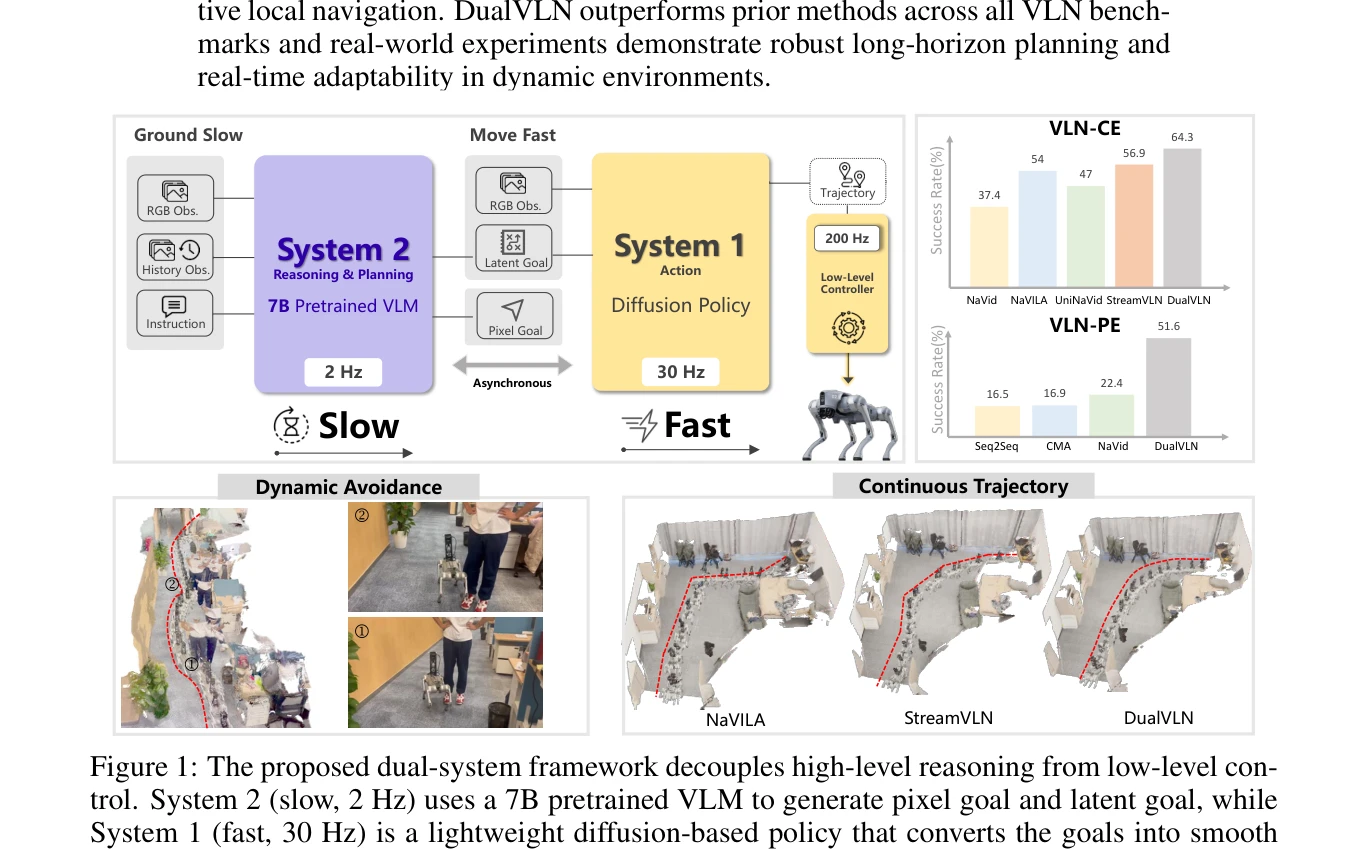
Figure 1: The proposed dual-system framework decouples high-level reasoning from low-level con-
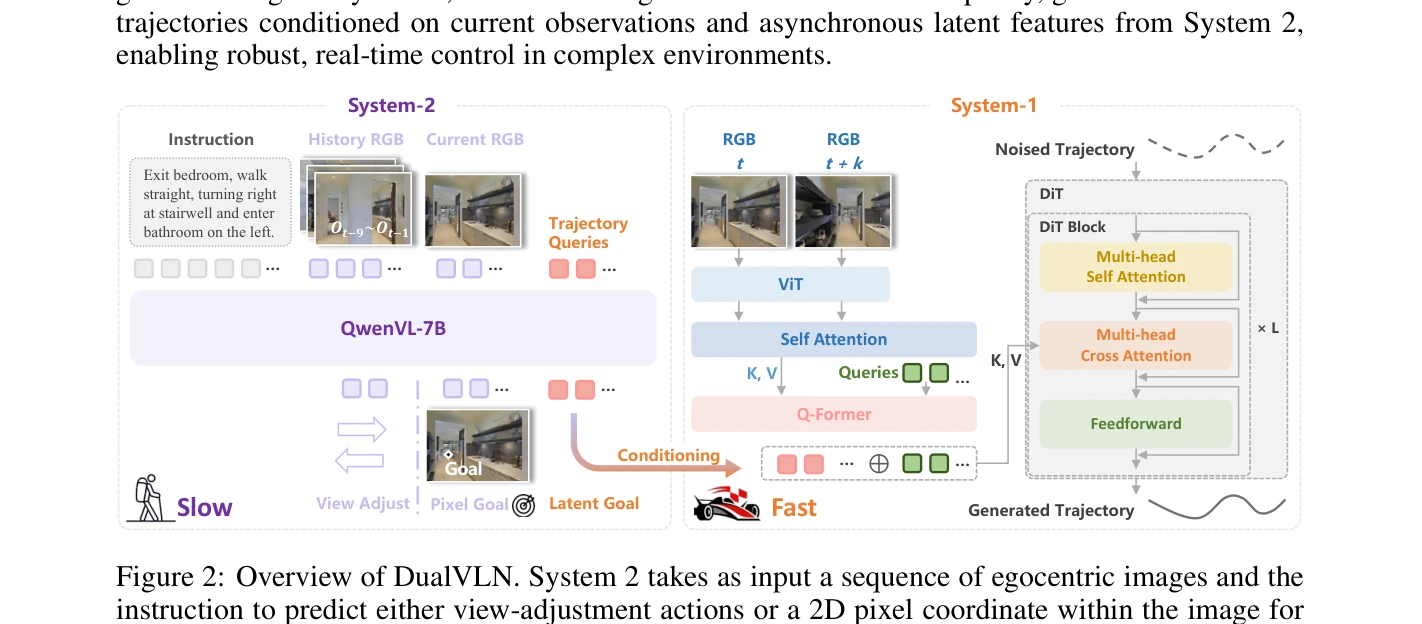
DualVLN은 Vision-Language Navigation을 위해 고수준 추론(System 2)과 저수준 제어(System 1)를 분리한 최초의 dual-system foundation model으로, VLM 기반 global planner와 Diffusion Transformer 기반 policy의 비동기 협력을 통해 실시간 제어와 동적 장애물 회피를 가능하게 한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: DualVLN은 Vision-Language Navigation 분야에서 VLM의 reasoning 능력과 diffusion policy의 real-time control 능력을 체계적으로 결합한 혁신적 접근법으로, 벤치마크와 실세계 실험 모두에서 뛰어난 성과를 입증하며 로봇 네비게이션의 실용적 배포에 큰 기여를 한다.