Essence
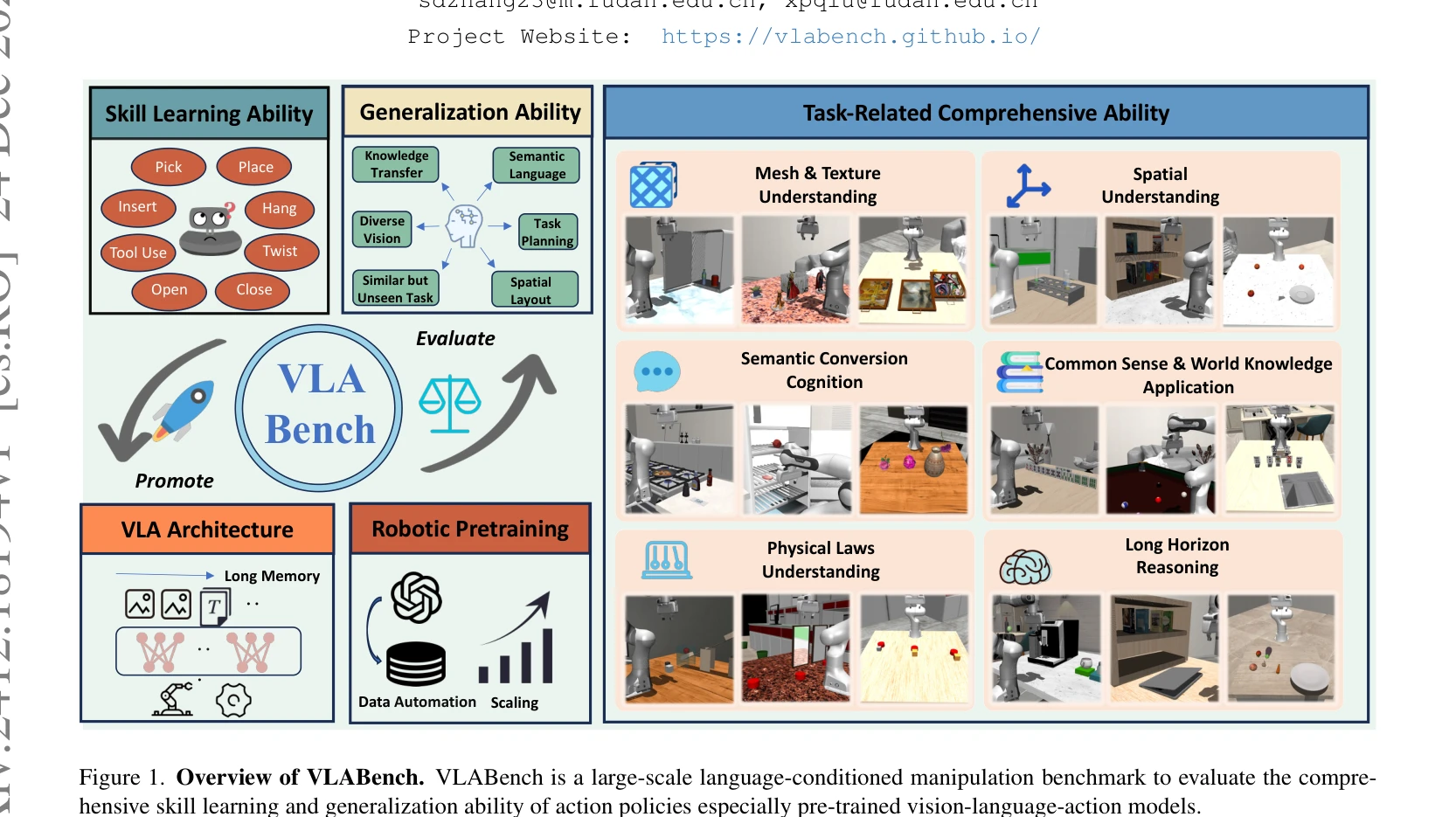
Figure 1. Overview of VLABench. VLABench is a large-scale language-conditioned manipulation benchmark to evaluate the co
VLABench는 Vision-Language-Action 모델의 능력을 평가하기 위해 설계된 대규모 로봇 조작 벤치마크로, 자연어 지시, 상식 이전, 장기 추론이 필요한 100개의 과제를 제공한다.
저자: Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, Xipeng Qiu | 날짜: 2024-12-24 | URL: https://arxiv.org/abs/2412.18194 📄 PDF
Figure 1. Overview of VLABench. VLABench is a large-scale language-conditioned manipulation benchmark to evaluate the co
VLABench는 Vision-Language-Action 모델의 능력을 평가하기 위해 설계된 대규모 로봇 조작 벤치마크로, 자연어 지시, 상식 이전, 장기 추론이 필요한 100개의 과제를 제공한다.
Figure 1. Overview of VLABench. VLABench is a large-scale language-conditioned manipulation benchmark to evaluate the co

Figure 3. Task examples in each dimension. The first row showcases examples of primitive tasks from Section 3.1, while t
총평: VLABench는 foundation model 기반의 로봇 조작 연구를 평가하기 위한 첫 번째 포괄적 벤치마크로서, 자연언어 지시, 상식 이전, 장기 추론 등 기존 벤치마크가 간과했던 중요한 차원들을 체계적으로 도입했다. 현 SOTA 모델들의 한계를 명확히 드러냄으로써 향후 VLA 및 embodied AI 연구 방향 설정에 중요한 역할을 할 것으로 예상된다.