Essence

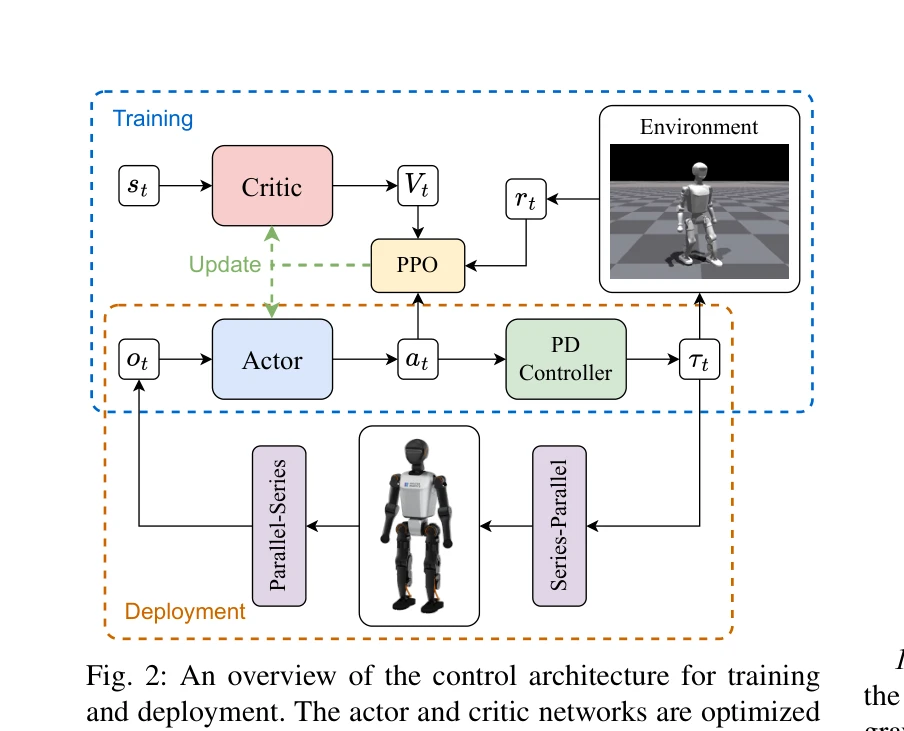
Fig. 1: Training, testing, and deployment on Booster T1
Booster Gym은 시뮬레이션에서 실제 로봇까지 humanoid robot locomotion을 위한 RL 기반 정책을 훈련하고 배포하는 end-to-end 프레임워크를 제시한다. 이 프레임워크는 domain randomization, 보상 함수 설계, parallel structures 처리 등을 포함하며 Booster T1 로봇에서 omnidirectional walking, disturbance resistance, terrain adaptability를 달성했다.