Essence
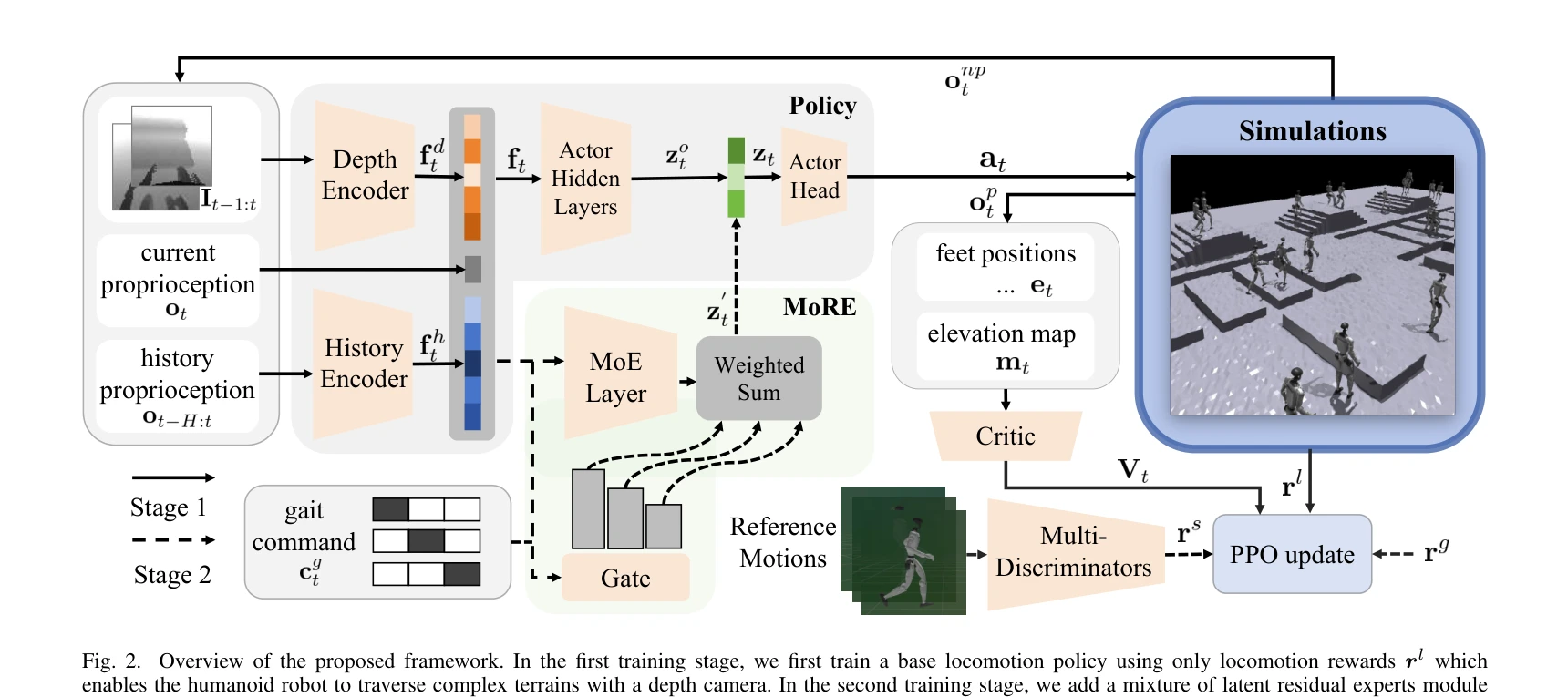
Fig. 2.
휴머노이드 로봇이 복잡한 지형을 인간다운 보행으로 횡단하기 위해 Mixture of Residual Experts (MoRE)와 다중 판별자를 활용한 2단계 RL 학습 프레임워크를 제안한다.
저자: Dewei Wang, Xinmiao Wang, Xinzhe Liu, Jiyuan Shi, Yingnan Zhao, Chenjia Bai, Xuelong Li | 날짜: 2025-06-10 | URL: https://arxiv.org/abs/2506.08840 📄 PDF
Fig. 2.
휴머노이드 로봇이 복잡한 지형을 인간다운 보행으로 횡단하기 위해 Mixture of Residual Experts (MoRE)와 다중 판별자를 활용한 2단계 RL 학습 프레임워크를 제안한다.

Fig. 1. Our framework leverages a two-stage training pipeline and the mixture
Fig. 2.
총평: 본 논문은 복잡 지형 횡단과 인간다운 다중 보행 학습을 동시에 달성하는 통합적 프레임워크를 제시하며, MoE 기반 residual 접근법과 다중 판별자 활용으로 방법론적 독창성을 보인다. 실제 로봇 배포 검증과 함께 기술적으로 견고하고 실무적 중요성이 높은 연구이다.