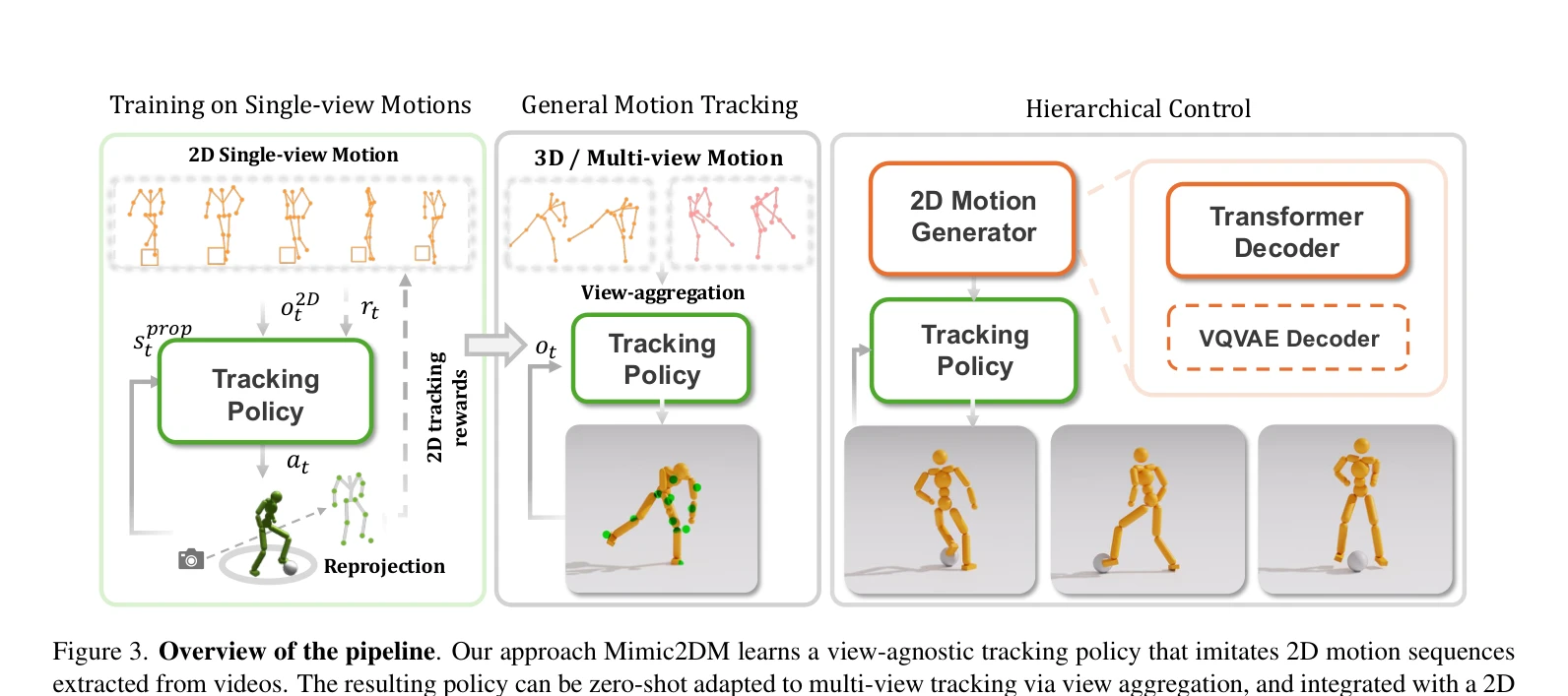
Essence
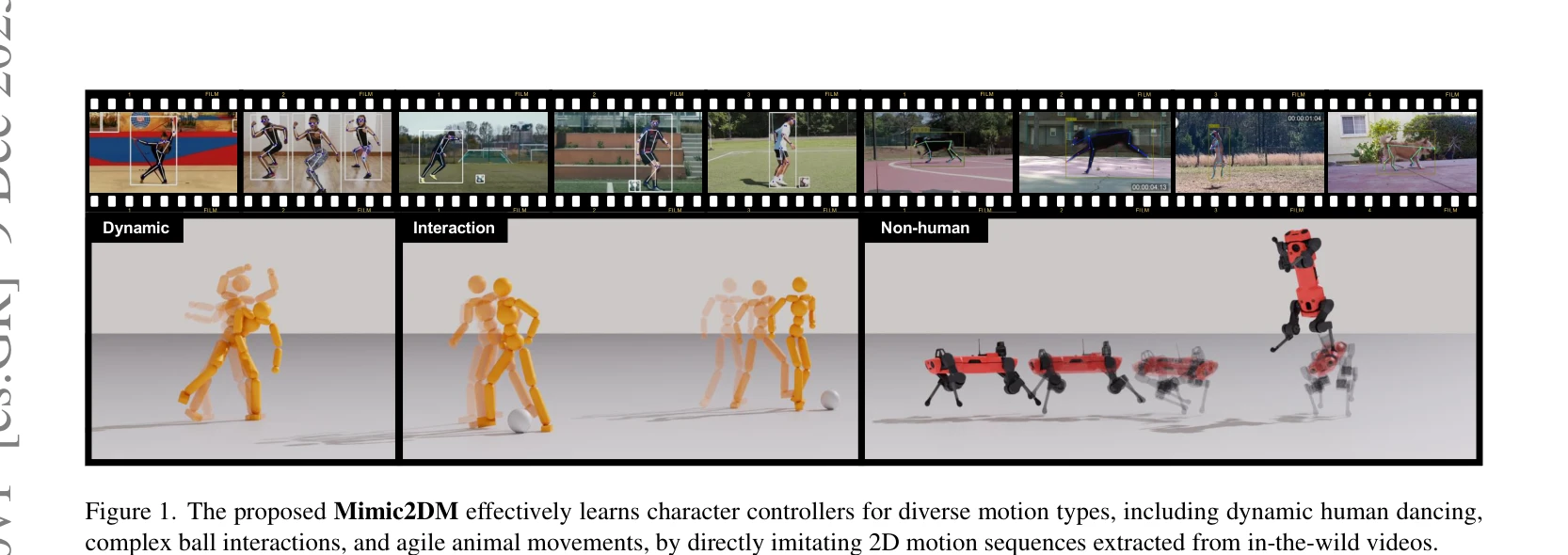
Figure 1. The proposed Mimic2DM effectively learns character controllers for diverse motion types, including dynamic hum
Mimic2DM은 비디오에서 추출한 2D 키포인트 궤적만을 사용하여 물리 기반 3D 캐릭터 제어 정책을 직접 학습하는 모션 모방 프레임워크이며, 재투영 오차 최소화와 RL을 통해 2D 데이터로부터 물리적으로 타당한 3D 동작을 합성한다.