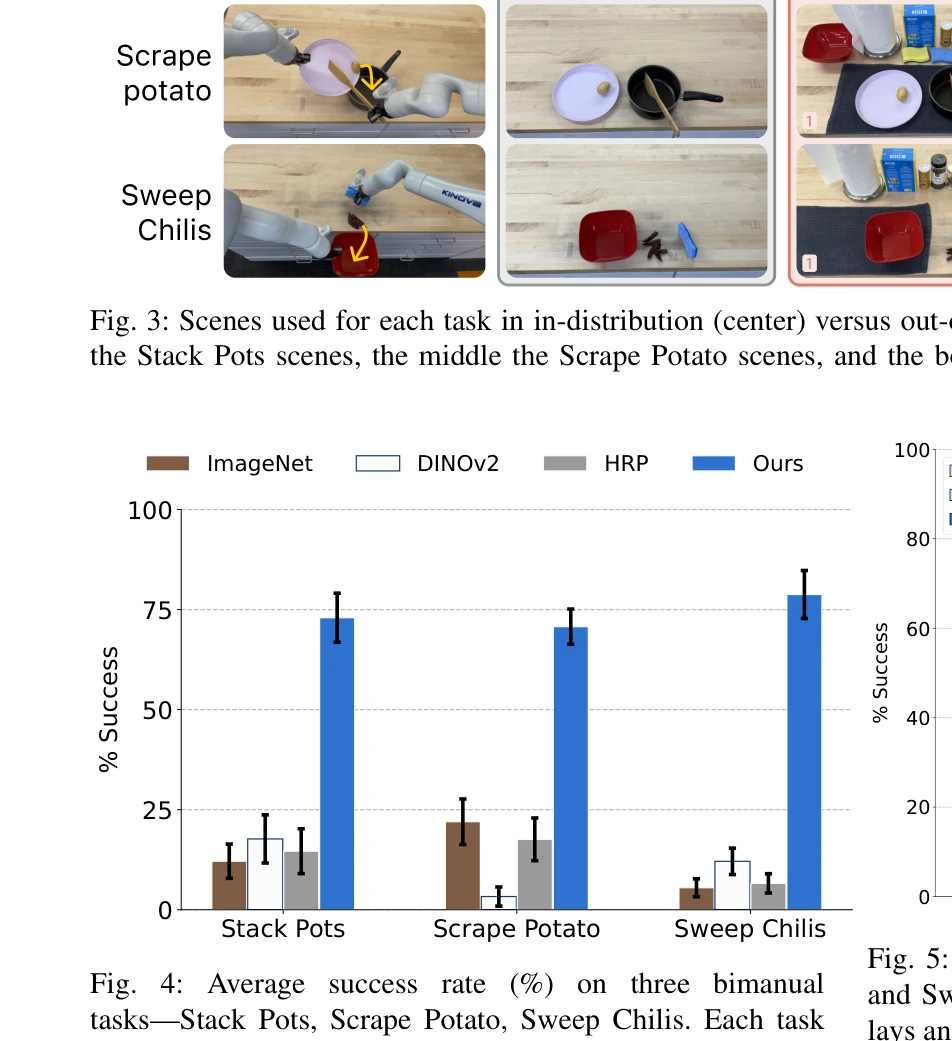
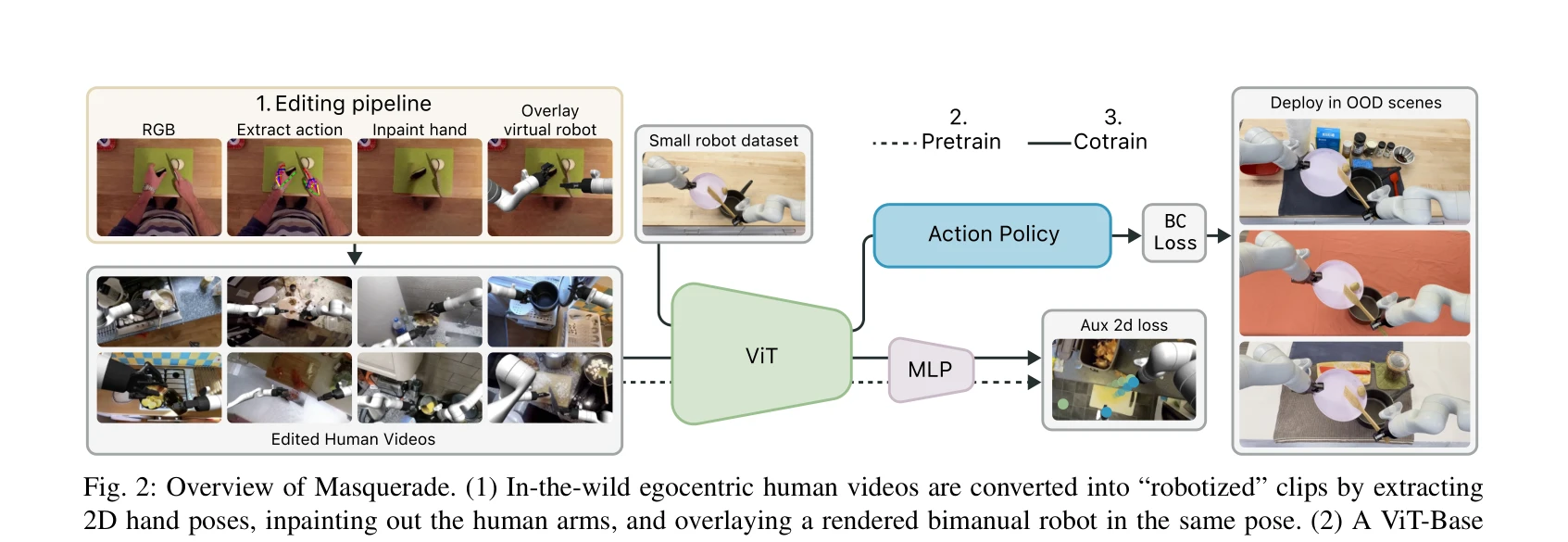
Essence

Fig. 1: Overview of Masquerade. Left: Large-scale in-the-wild egocentric human videos are edited to obtain “robotized”
Masquerade는 in-the-wild 인간 영상을 데이터 편집을 통해 로봇화된 시연으로 변환하고, 이를 통해 사전학습된 visual encoder로 로봇 조작 정책을 학습하는 방법을 제안한다. 675K 프레임의 편집된 인간 영상으로 사전학습 후 50개의 로봇 시연으로 fine-tuning하여 기존 방법 대비 5-6배 향상된 성능을 달성한다.