Essence
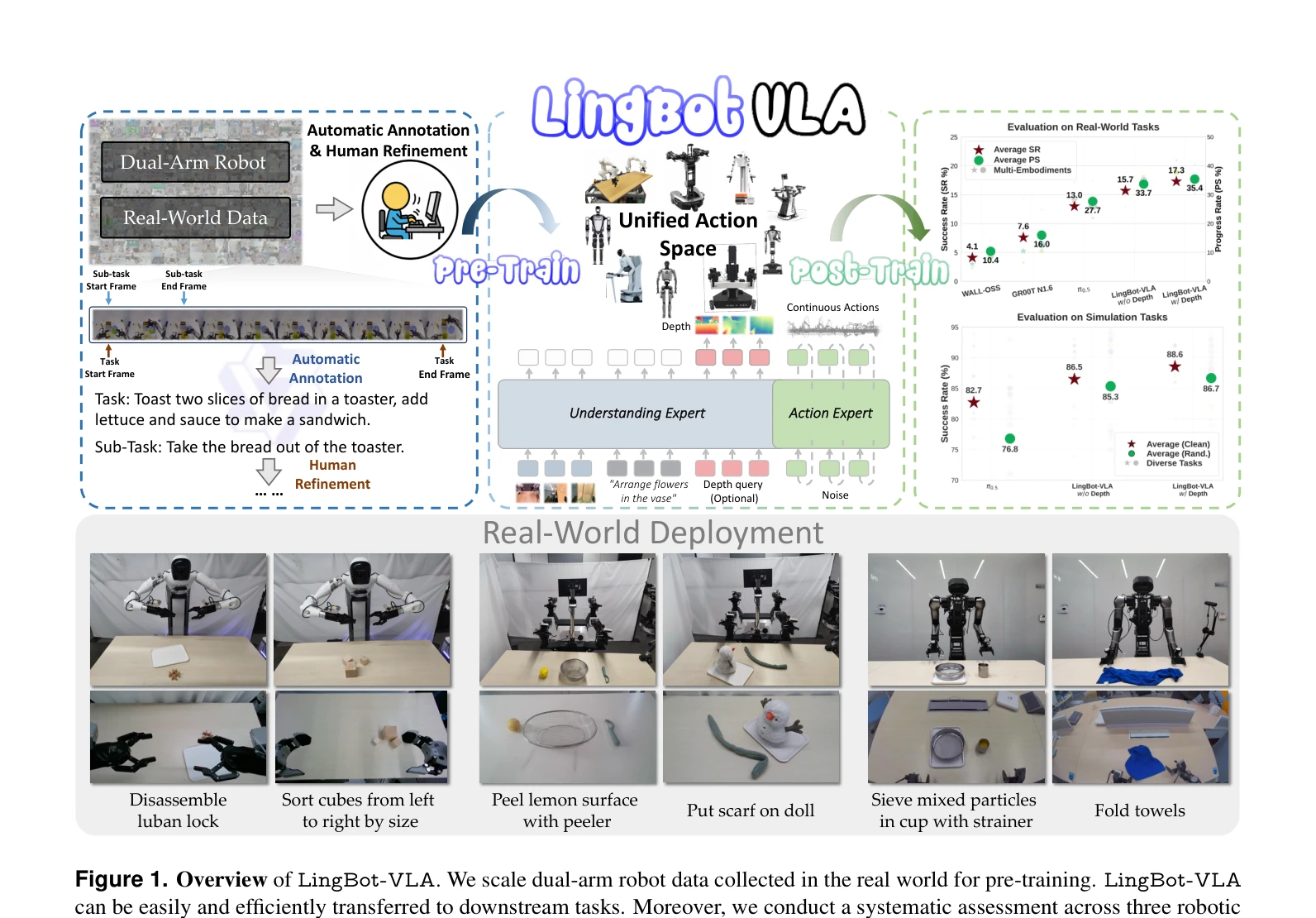
Figure 1. Overview of LingBot-VLA. We scale dual-arm robot data collected in the real world for pre-training. LingBot-VL
LingBot-VLA는 약 20,000시간의 실제 로봇 데이터로 학습한 Vision-Language-Action 기초 모델로, 효율적인 학습과 다중 플랫폼 일반화 능력을 갖춘다.
저자: Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, Yiyu Ren, Kejia Zhang, Hui Yu, Jingmei Zhao, Shuai Zhou, Zhenqi Qiu, Houlong Xiong, Ziyu Wang, Zechen Wang, Ran Cheng, Yong-Lu Li, Yongtao Huang, Xing Zhu, Yujun Shen, Kecheng Zheng | 날짜: 2026-01-26 | URL: https://arxiv.org/abs/2601.18692 📄 PDF
Figure 1. Overview of LingBot-VLA. We scale dual-arm robot data collected in the real world for pre-training. LingBot-VL
LingBot-VLA는 약 20,000시간의 실제 로봇 데이터로 학습한 Vision-Language-Action 기초 모델로, 효율적인 학습과 다중 플랫폼 일반화 능력을 갖춘다.

Figure 2. Visualization of pre-training dataset used by LingBot-VLA.
Figure 1. Overview of LingBot-VLA. We scale dual-arm robot data collected in the real world for pre-training. LingBot-VL
총평: LingBot-VLA는 실제 로봇 학습의 스케일링 거동을 최초로 실증하고 대규모 다양한 데이터와 효율적 훈련 인프라를 통해 실용적이고 일반화 가능한 VLA 기초 모델을 제시하며, 오픈 소스 공개로 로봇 학습 커뮤니티에 현저한 기여를 한다.