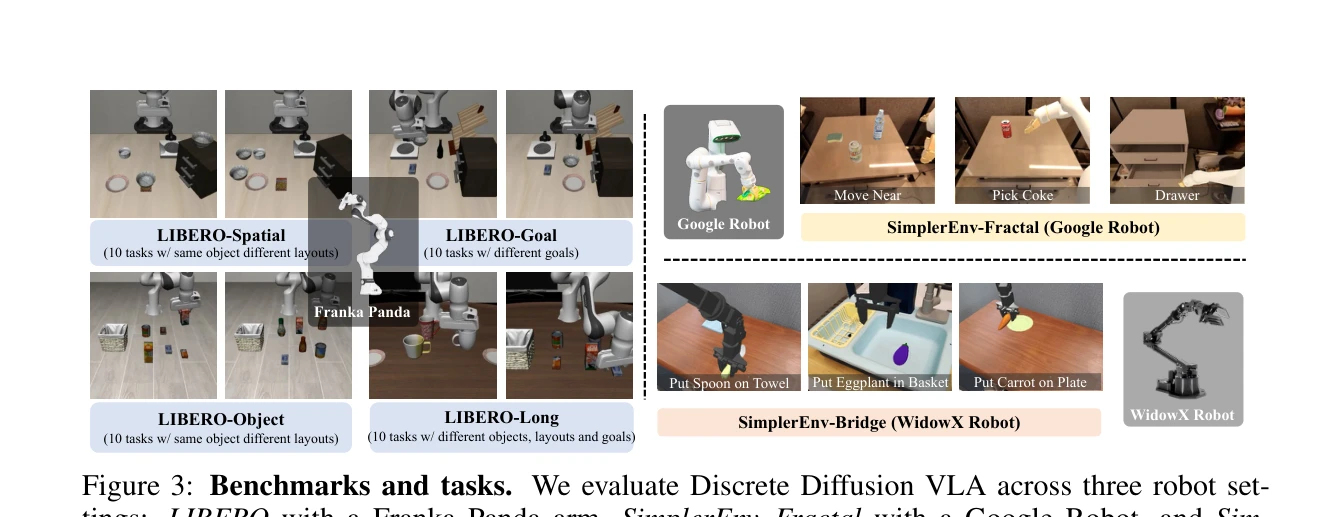
저자: Zhixuan Liang, Yizhuo Li, Tianshuo Yang, Chengyue Wu, Sitong Mao, Tian Nian, Liuao Pei, Shunbo Zhou, Xiaokang Yang, Jiangmiao Pang, Yao Mu, Ping Luo | 날짜: 2025-08-27 | URL: https://arxiv.org/abs/2508.20072 📄 PDF
Essence
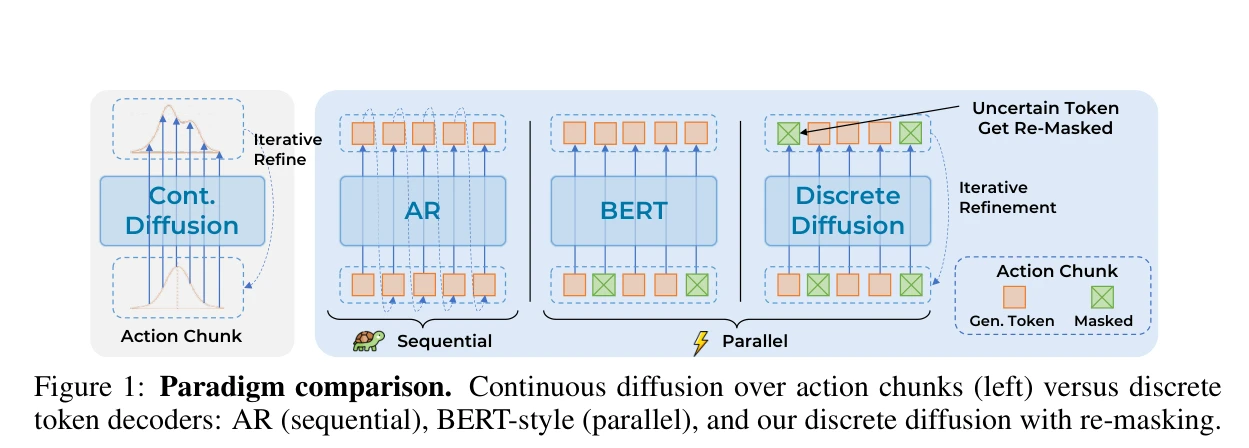
Figure 1: Paradigm comparison. Continuous diffusion over action chunks (left) versus discrete
Vision-Language-Action (VLA) 모델에 discrete diffusion을 적용하여 action token을 적응적으로 디코딩하는 unified transformer 정책을 제시한다. 이를 통해 자동회귀 방식의 순서 제약을 극복하고 분리된 decoder 구조의 문제를 해결한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 discrete diffusion을 VLA에 처음 적용하여 unified transformer 구조로 vision, language, action을 통합하는 혁신적인 접근을 제시하며, 여러 로봇 플랫폼에서 강력한 성과를 입증하고 향후 대규모 VLA 연구의 기초를 마련하는 중요한 기여를 한다.