Essence
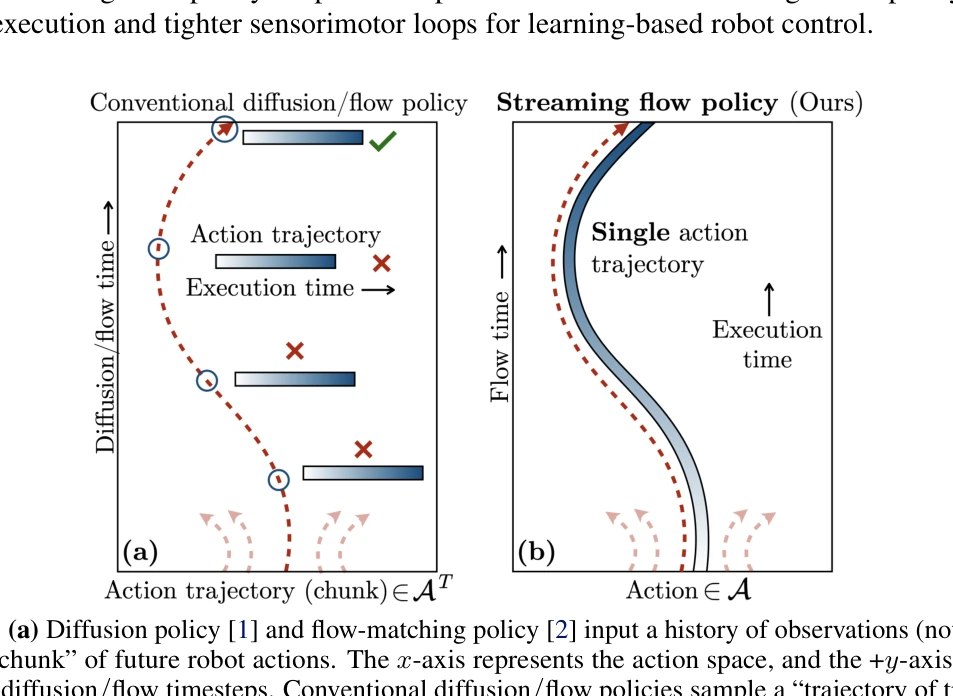
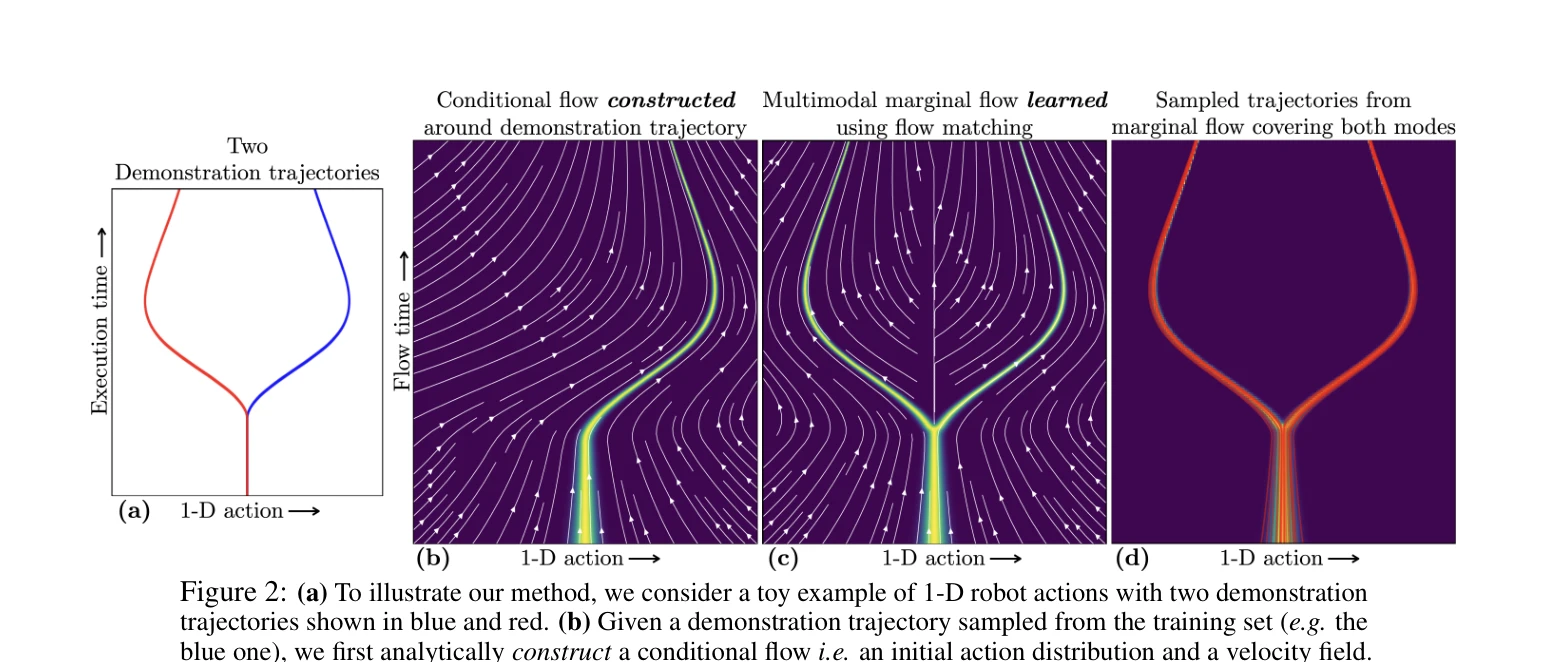
Figure 1: (a) Diffusion policy [1] and flow-matching policy [2] input a history of observations (not shown) to
Action trajectory를 flow trajectory로 취급하여 diffusion/flow-matching 정책을 단순화하고, 흐름 샘플링 중 실시간으로 로봇에 action을 스트리밍할 수 있는 streaming flow policy를 제안한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 action trajectory를 flow trajectory로 취급하는 근본적으로 새로운 관점을 제시하여 diffusion/flow policy의 계산 효율성과 반응성을 크게 개선한 논문이다. Streaming generation이라는 실용적 이점과 이론적 기반(flow matching)의 조화, 그리고 로봇 제어의 특성을 활용한 설계가 돋보이는 우수한 연구다.