저자: Rongyu Zhang, Menghang Dong, Yuan Zhang, Liang Heng, Xiaowei Chi, Gaole Dai, Li Du, Yuan Du, Shanghang Zhang | 날짜: 2025-03-26 | URL: https://arxiv.org/abs/2503.20384 📄 PDF
Essence
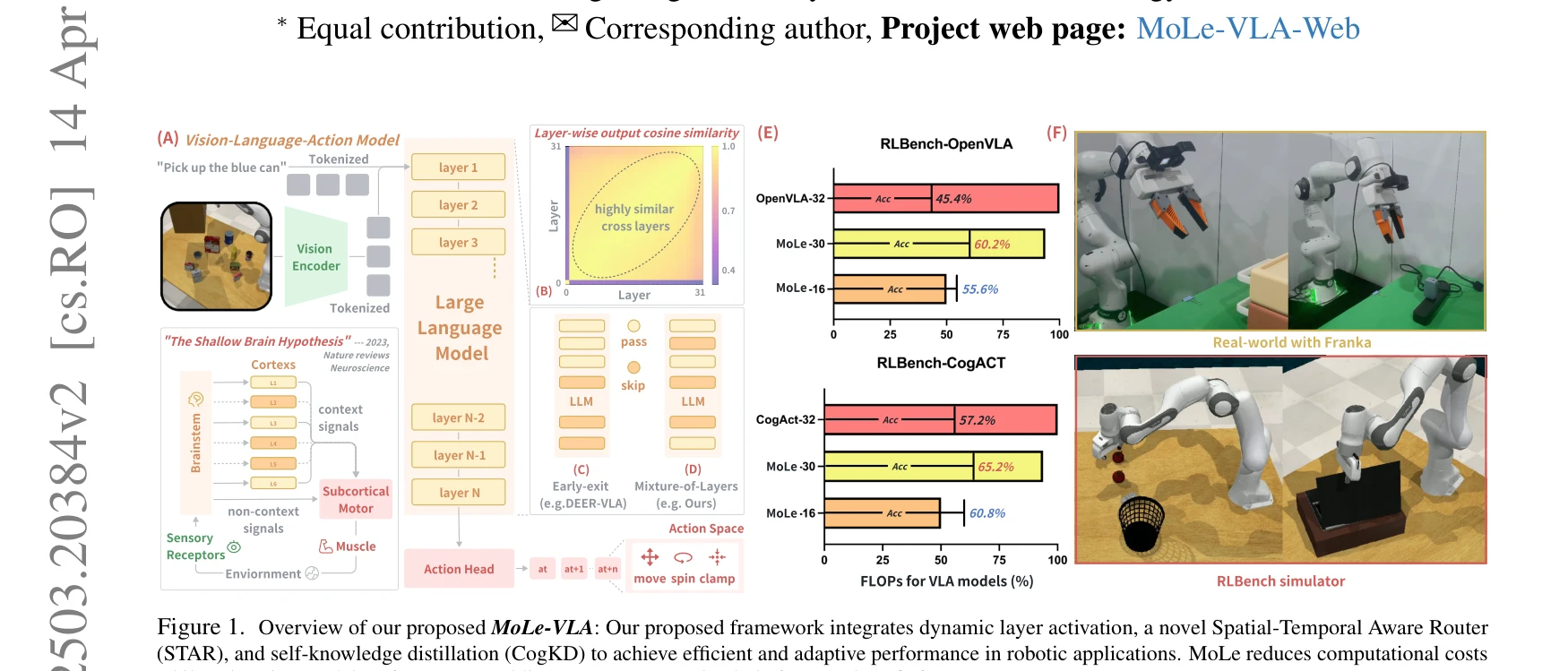
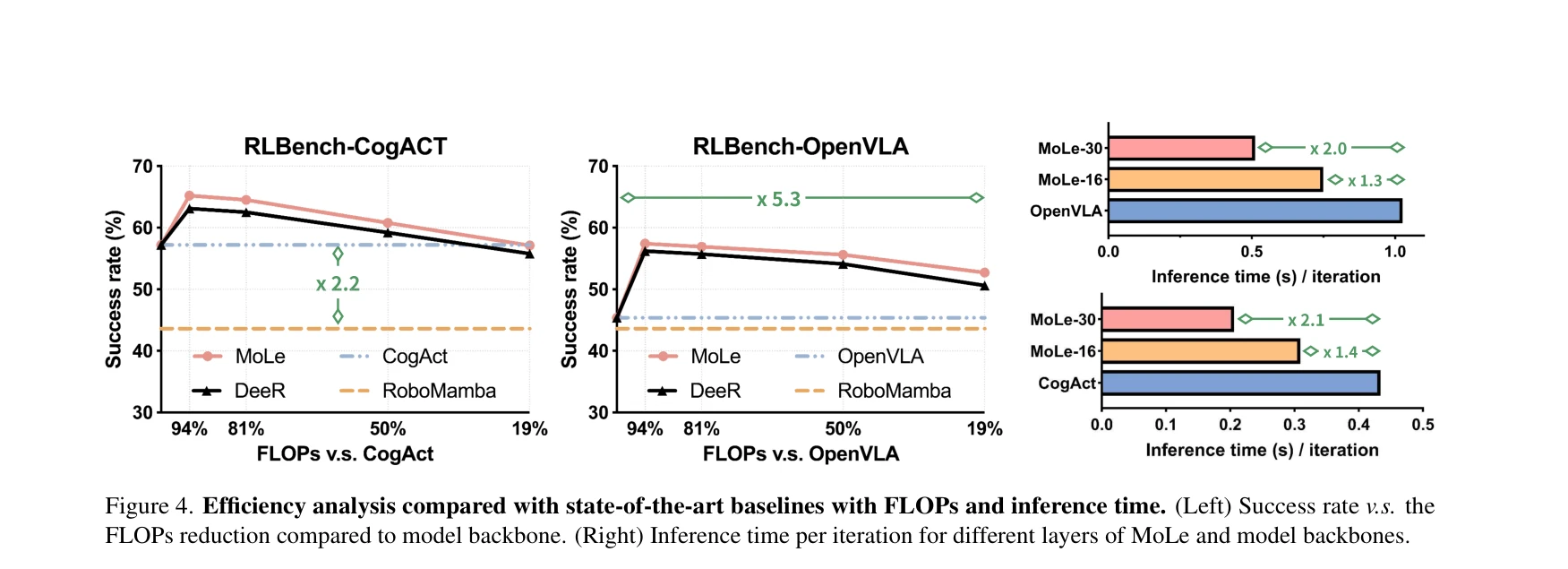
Figure 1. Overview of our proposed MoLe-VLA: Our proposed framework integrates dynamic layer activation, a novel Spatial
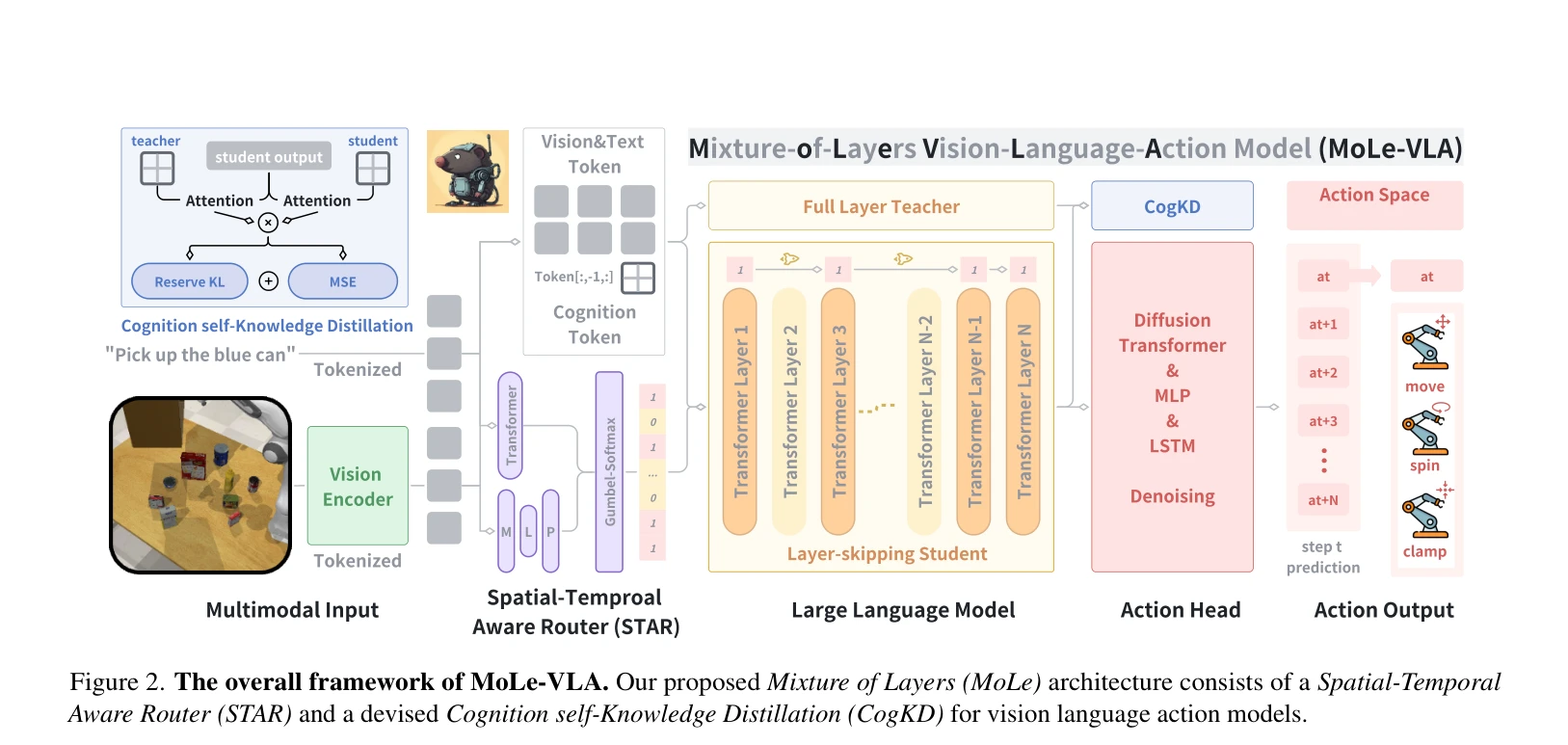
MoLe-VLA는 Mixture-of-Layers 아키텍처와 Spatial-Temporal Aware Router(STAR)를 통해 LLM의 불필요한 레이어를 동적으로 스킵하여 로봇 조작 작업의 계산 효율을 5.6배 향상시키면서 8% 성능 개선을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: MoLe-VLA는 신경과학 이론과 효율적인 AI 기술을 혁신적으로 결합하여 로봇 제어의 계산-성능 트레이드오프 문제를 크게 개선한 우수한 연구이다. 공간-시간 인식 라우팅과 인지 기반 지식 증류의 설계가 독창적이며, 시뮬레이션과 실제 환경에서의 실증 결과가 설득력 있다.