저자: Yunfei Li, Xiao Ma, Jiafeng Xu, Yu Cui, Zhongren Cui, Zhigang Han, Liqun Huang, Tao Kong, Yuxiao Liu, Hao Niu, Wanli Peng, Jingchao Qiao, Zeyu Ren, Haixin Shi, Zhi Su, Jiawen Tian, Yuyang Xiao, Shenyu Zhang, Liwei Zheng, Hang Li, Yonghui Wu | 날짜: 2025-12-01 | URL: https://arxiv.org/abs/2512.01801 📄 PDF
Essence
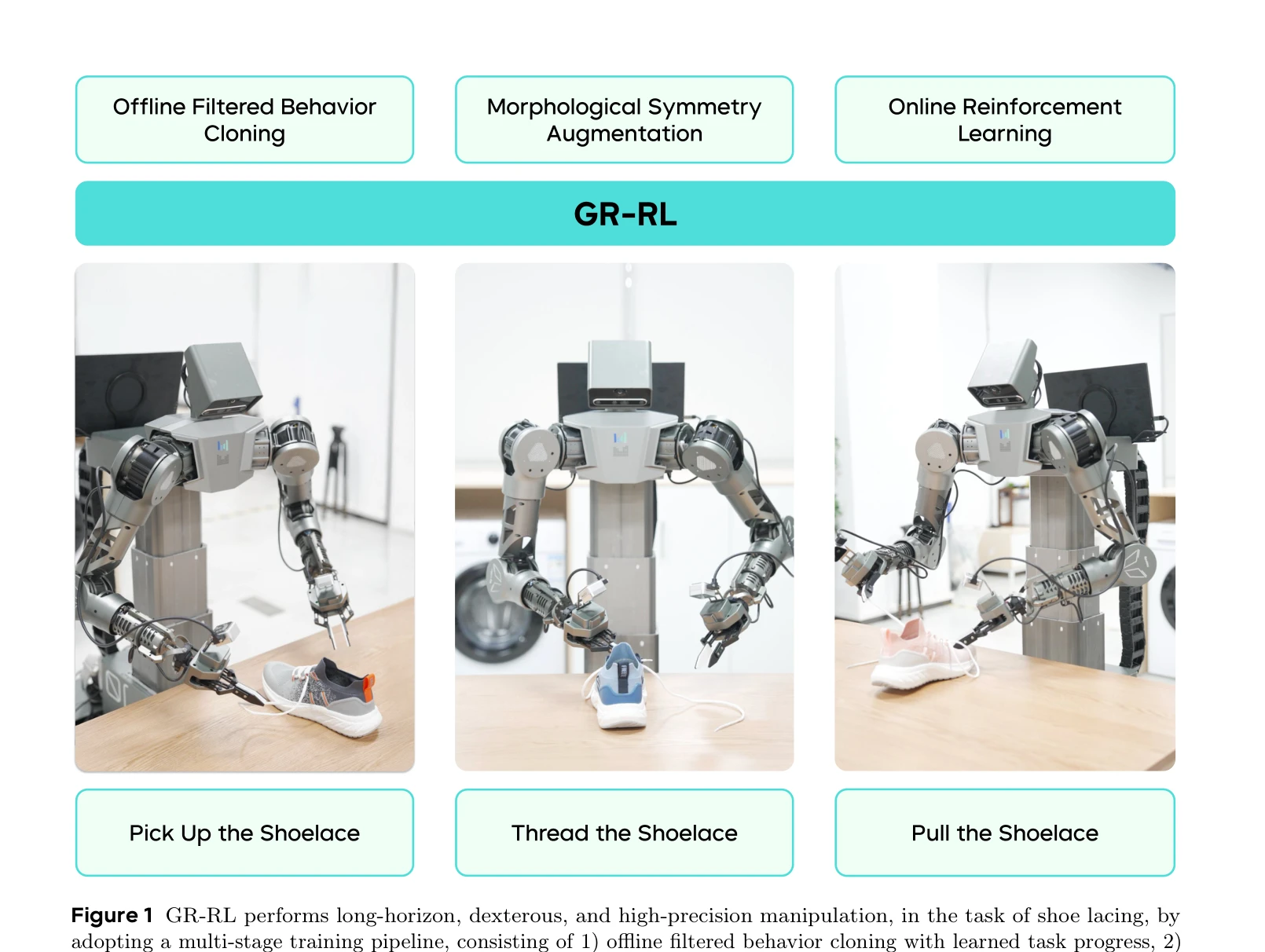
Figure 1 GR-RL performs long-horizon, dexterous, and high-precision manipulation, in the task of shoe lacing, by
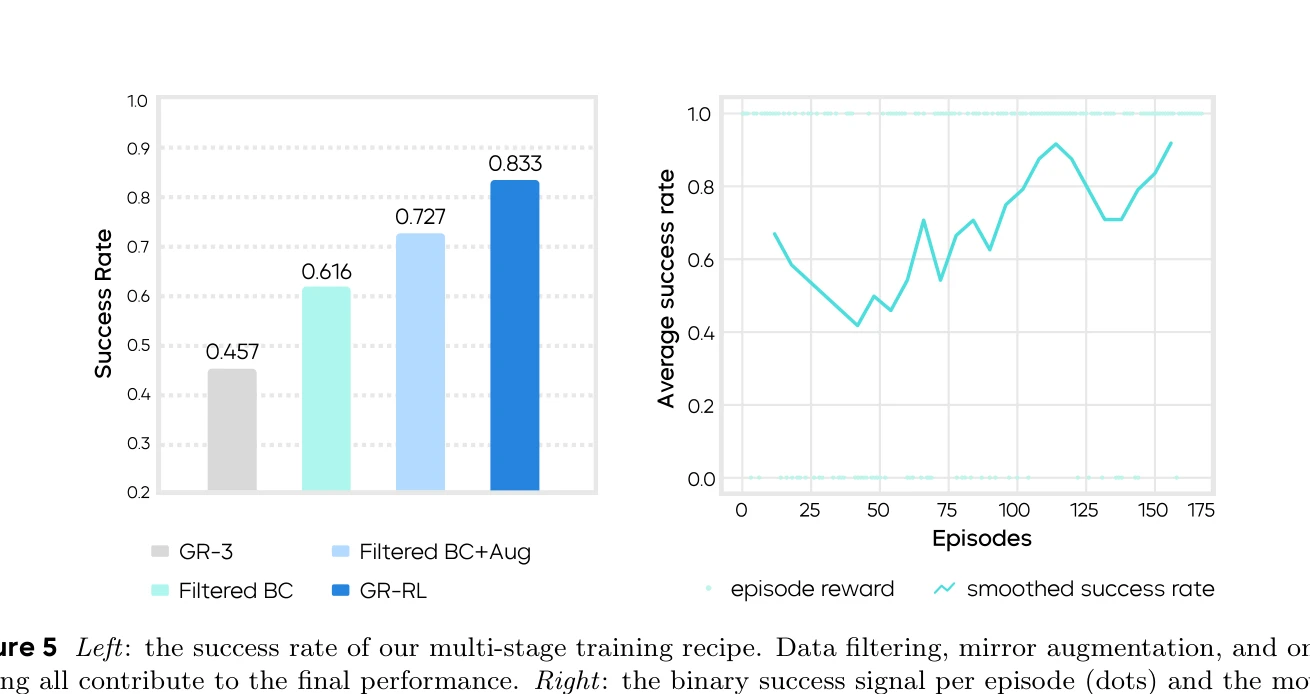
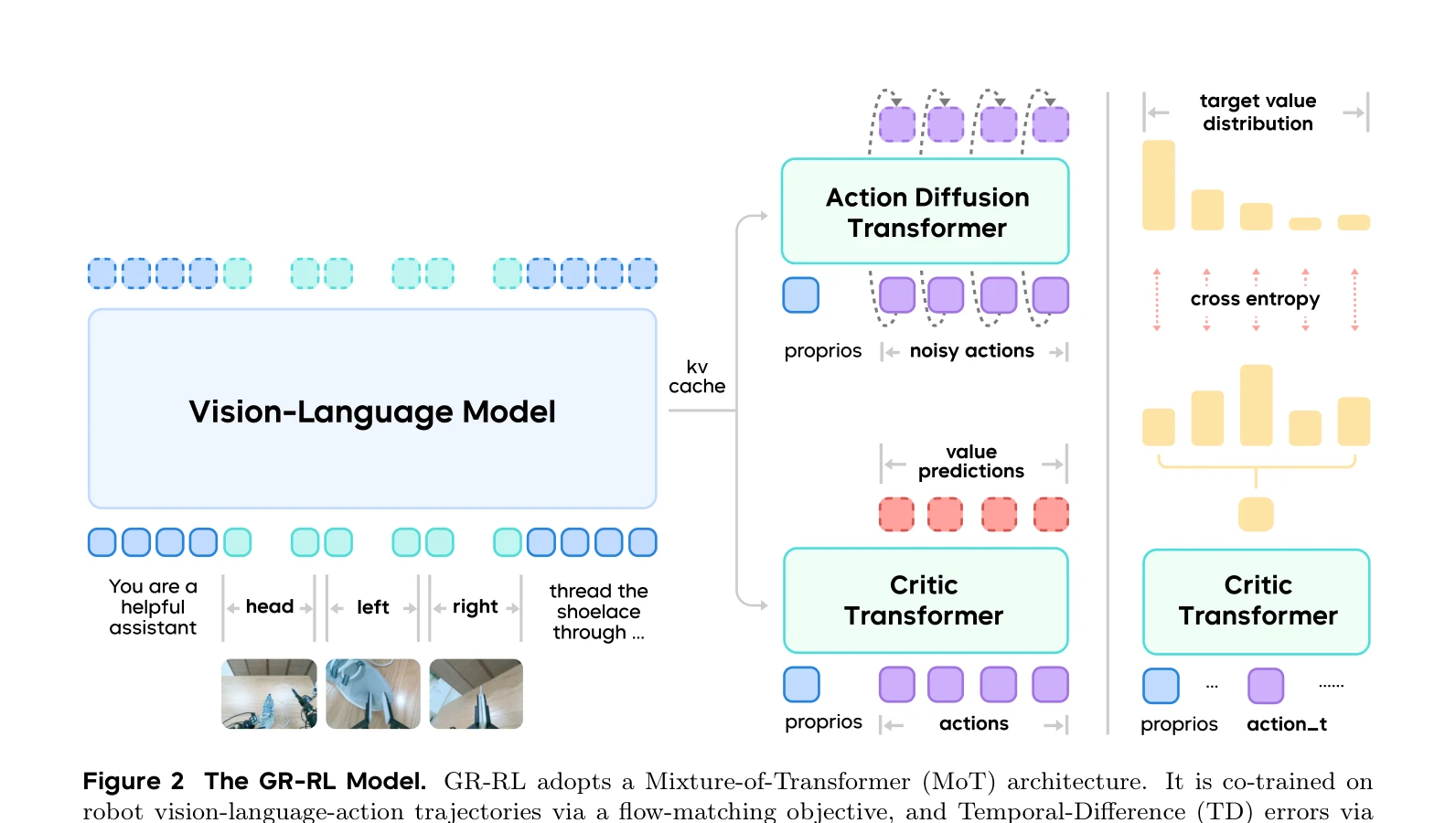
GR-RL은 일반적인 vision-language-action (VLA) 정책을 다단계 학습 파이프라인(데이터 필터링, 형태 대칭 증강, 온라인 RL)을 통해 장기 복잡 조작을 위한 고정밀 전문가 정책으로 변환하는 로봇 학습 프레임워크이다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: GR-RL은 인간 시연의 부분최적성과 학습-배포 불일치라는 실질적 문제를 체계적으로 해결하는 실용적인 다단계 파이프라인을 제시하며, 신발끈 꿰기와 같은 극도로 정밀한 조작 과제를 성공시킴으로써 로봇 기초 모델의 전문화 방향을 제시하는 중요한 기여를 한다.