Essence
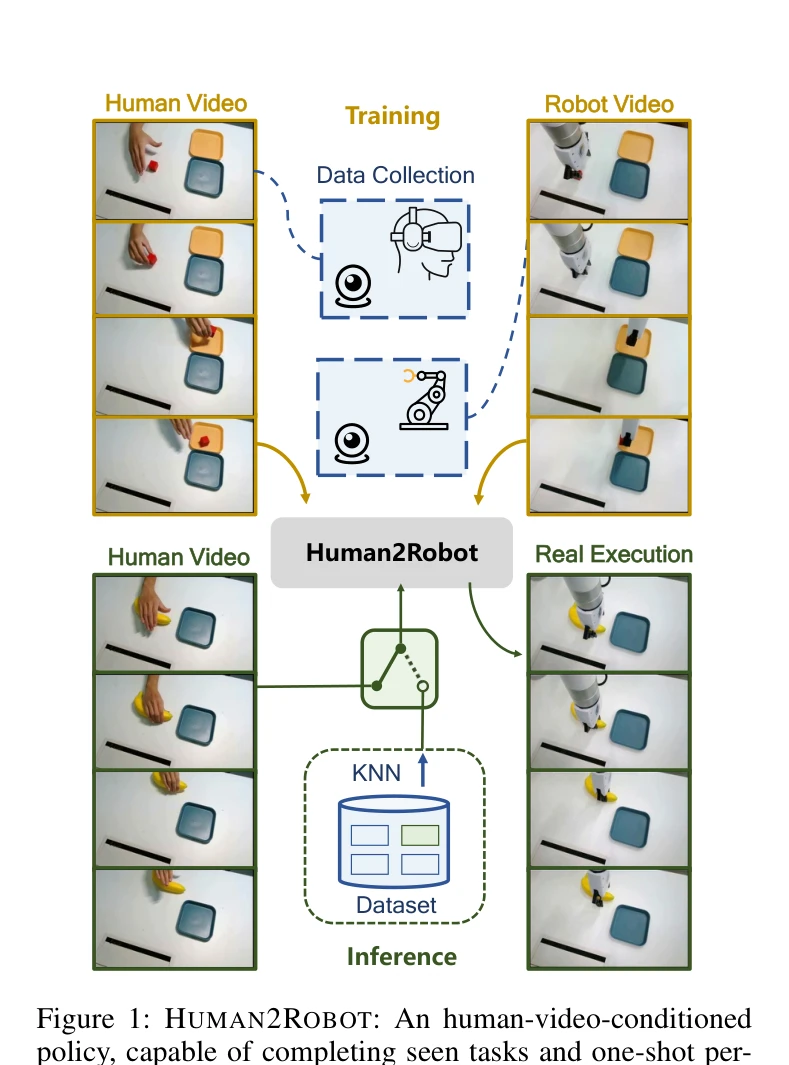
Figure 1: HUMAN2ROBOT: An human-video-conditioned
VR 원격조종으로 수집한 정밀하게 정렬된 인간-로봇 비디오 쌍 데이터셋 H&R과 이를 활용한 Human2Robot 프레임워크를 제시하여, Video Prediction Model을 통해 인간 동작으로부터 로봇 동작을 프레임 수준에서 학습하고 미학습 태스크에 일반화한다.
저자: Sicheng Xie, Haidong Cao, Zejia Weng, Zhen Xing, Haoran Chen, Shiwei Shen, Jiaqi Leng, Zuxuan Wu, Yu-Gang Jiang | 날짜: 2025-02-23 | URL: https://arxiv.org/abs/2502.16587 📄 PDF
Figure 1: HUMAN2ROBOT: An human-video-conditioned
VR 원격조종으로 수집한 정밀하게 정렬된 인간-로봇 비디오 쌍 데이터셋 H&R과 이를 활용한 Human2Robot 프레임워크를 제시하여, Video Prediction Model을 통해 인간 동작으로부터 로봇 동작을 프레임 수준에서 학습하고 미학습 태스크에 일반화한다.
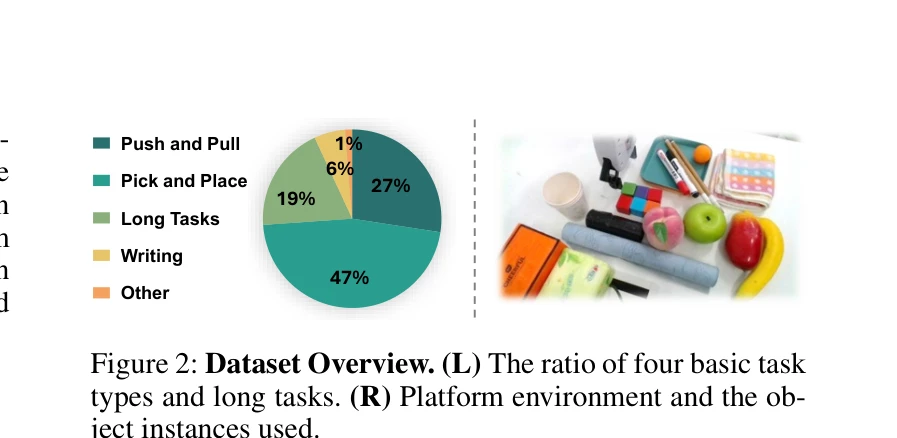
Figure 2: Dataset Overview. (L) The ratio of four basic task
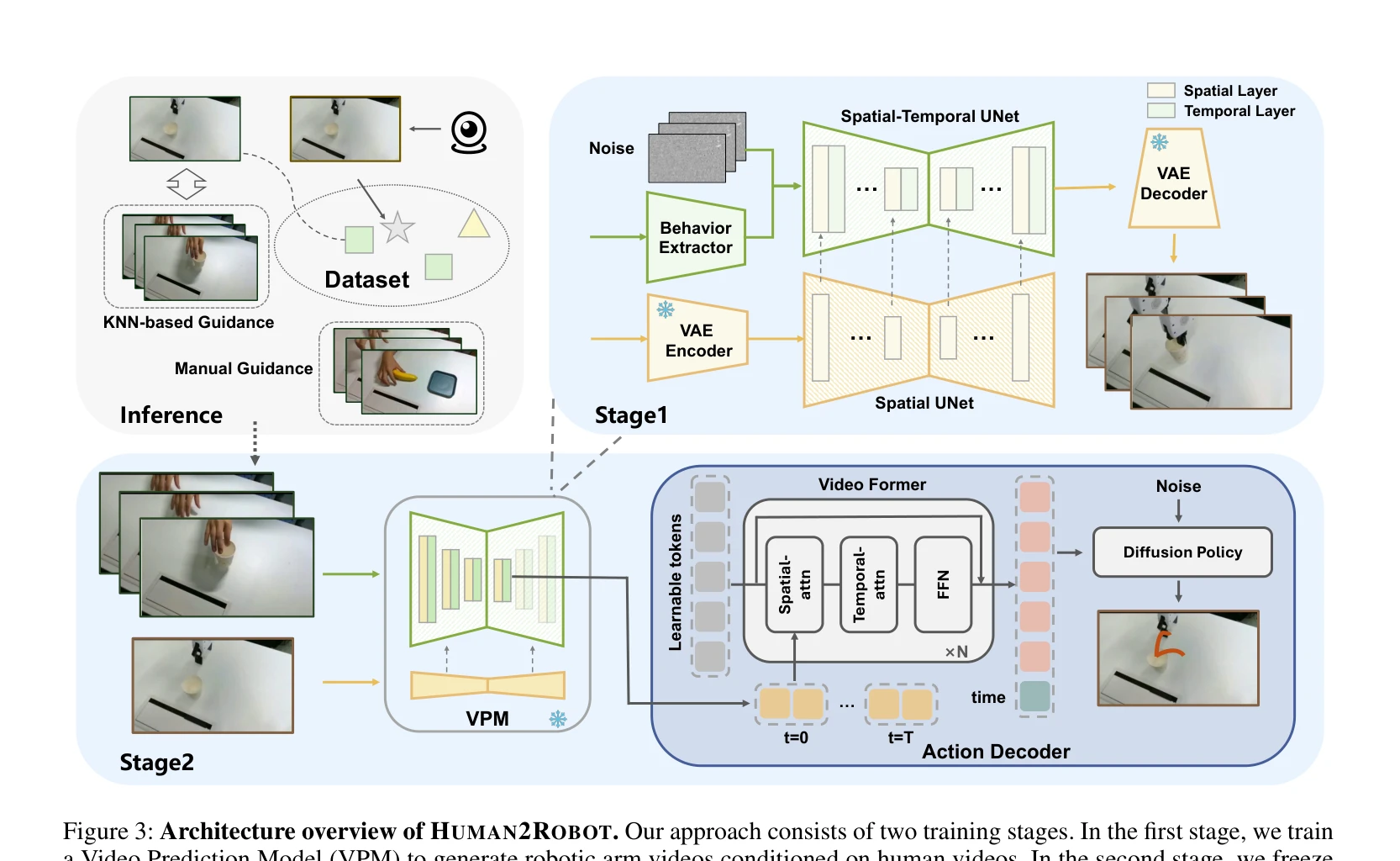
Figure 3: Architecture overview of HUMAN2ROBOT. Our approach consists of two training stages. In the first stage, we tra
총평: VR 원격조종을 통한 정밀한 데이터 수집과 conditional video generation 패러다임의 결합으로 인간-로봇 학습의 근본적 한계를 해결한 영향력 있는 연구이다. 다만 embodiment gap 문제의 미해결과 평가 범위의 제한이 실제 적용성을 다소 제약한다.