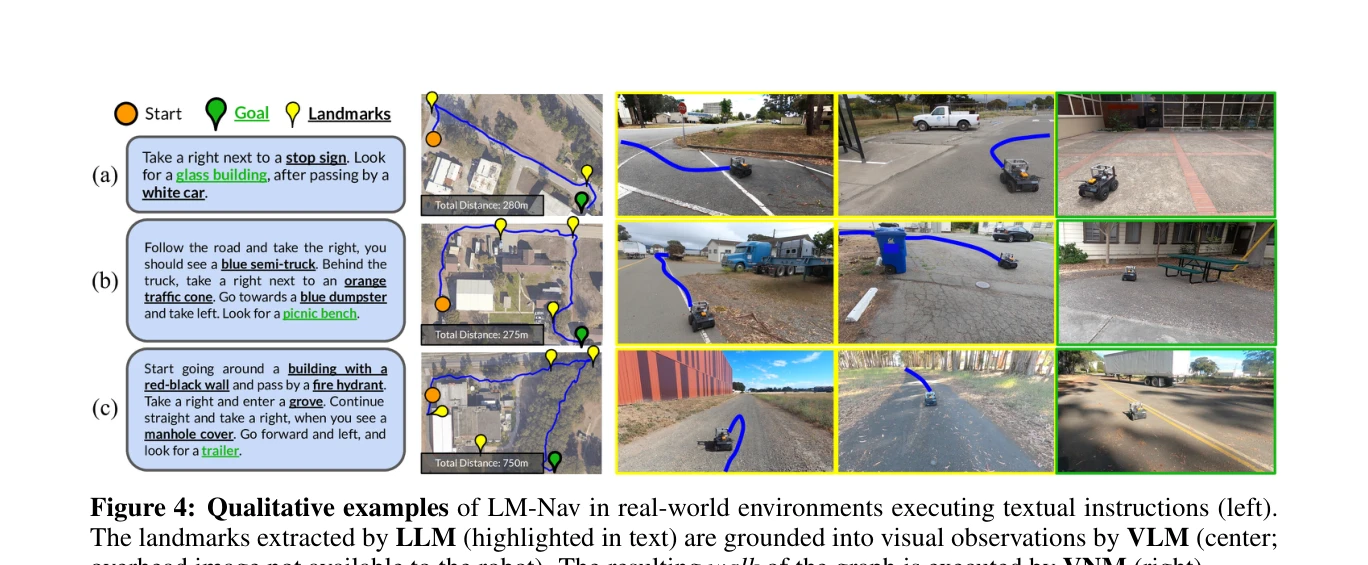
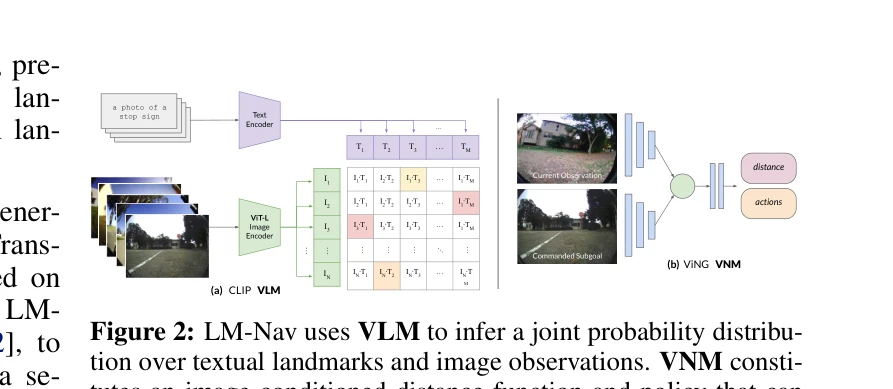
Essence
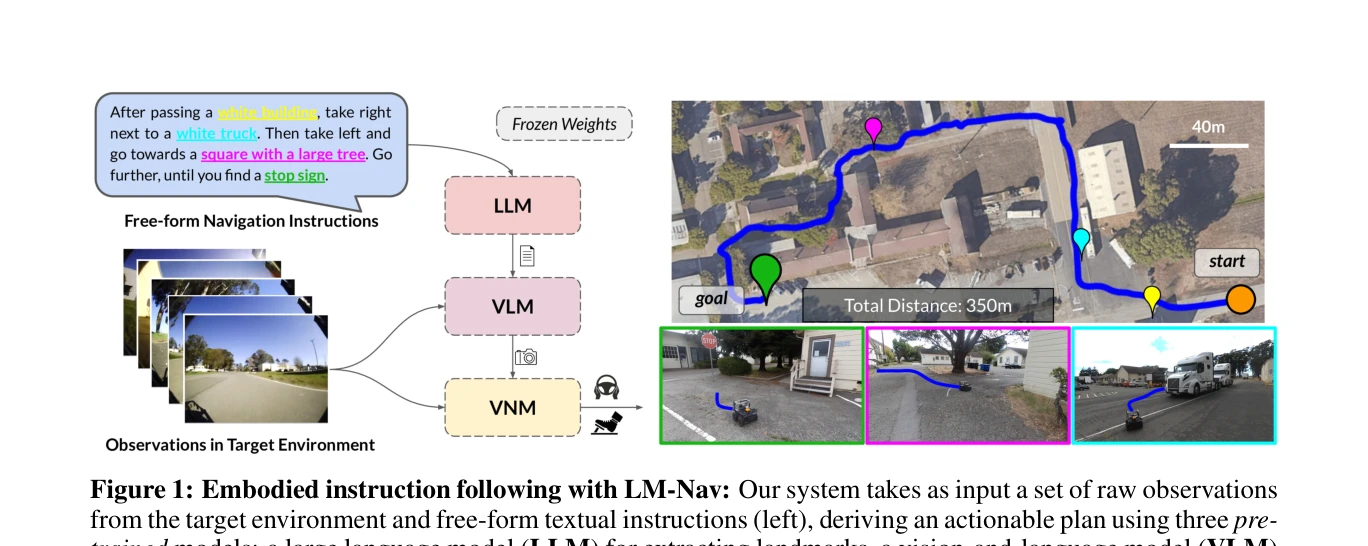
Figure 1: Embodied instruction following with LM-Nav: Our system takes as input a set of raw observations
LM-Nav는 GPT-3, CLIP, ViNG 세 가지 사전학습된 모델을 조합하여 자연언어 명령으로 로봇이 실제 환경에서 네비게이션을 수행하는 시스템이다. 로봇 데이터에 대한 언어 주석 없이도 복잡한 실외 환경에서 장거리 네비게이션을 실현한다.