저자: Letian Fu, Huang Huang, Gaurav Datta, Lawrence Yunliang Chen, William Chung-Ho Panitch, Fangchen Liu, Hui Li, Ken Goldberg | 날짜: 2024-08-28 | URL: https://arxiv.org/abs/2408.15980 📄 PDF
Essence

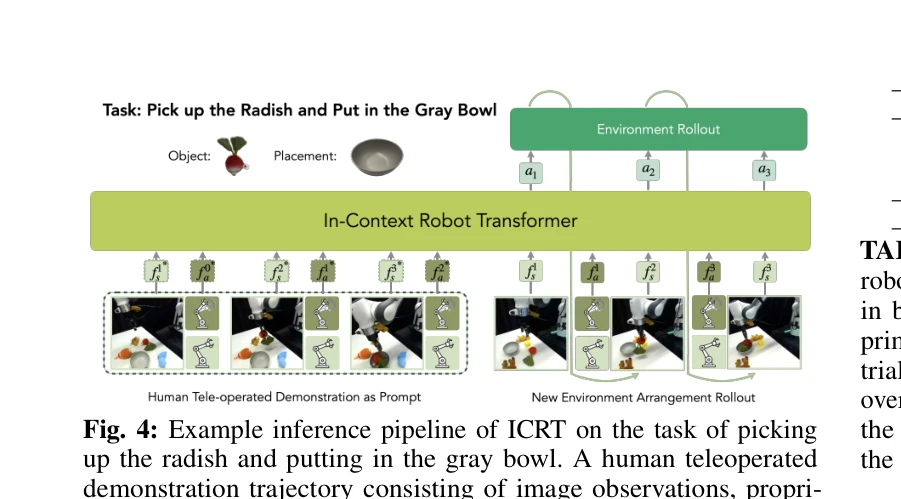
Fig. 1: In-Context Robot Transformer (ICRT): A robot foundation model with in-context imitation learning capabilities. I
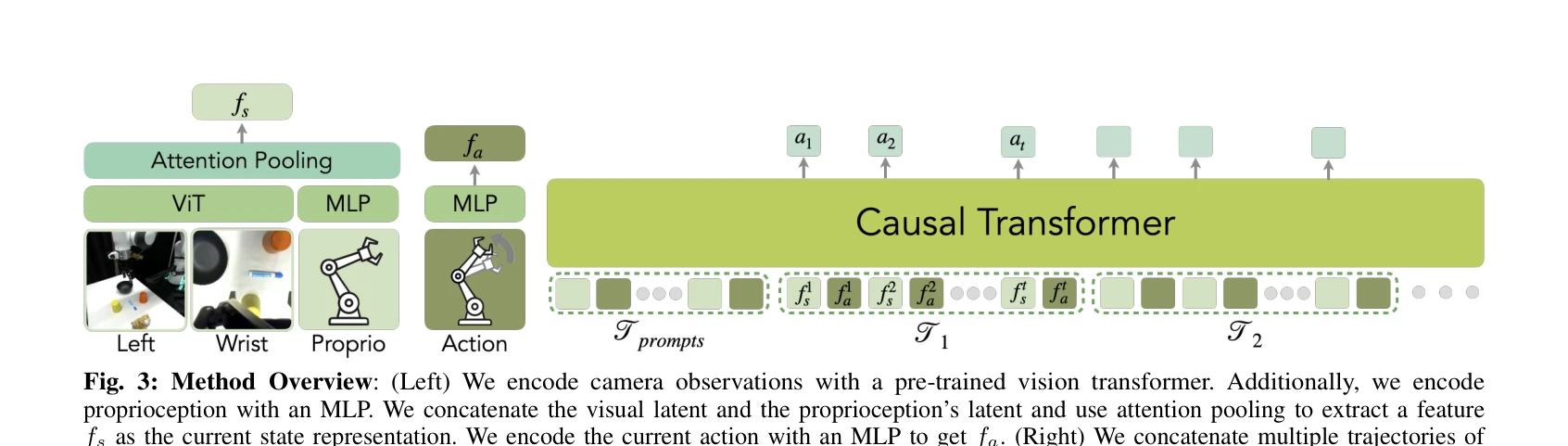
로봇이 새로운 작업을 수행할 때 정책 파라미터 업데이트 없이 입력 단계에서 제공된 문맥 정보를 해석하는 In-Context Robot Transformer (ICRT)를 제안한다. ICRT는 감각-운동 궤적에 대한 자동회귀 다음-토큰 예측을 통해 훈련 없이 새로운 작업을 유연하게 실행할 수 있다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: ICRT는 실제 로봇에서 처음으로 효과적인 문맥 내 학습을 보여주며, 간단한 다음-토큰 예측 프레임워크로 복잡한 시연 기반 학습을 가능하게 한다. 로봇 기초 모델의 실용성을 크게 향상시키는 의미 있는 기여이나, 일반화 범위와 기술적 깊이 면에서 추가 검증이 필요하다.