Essence
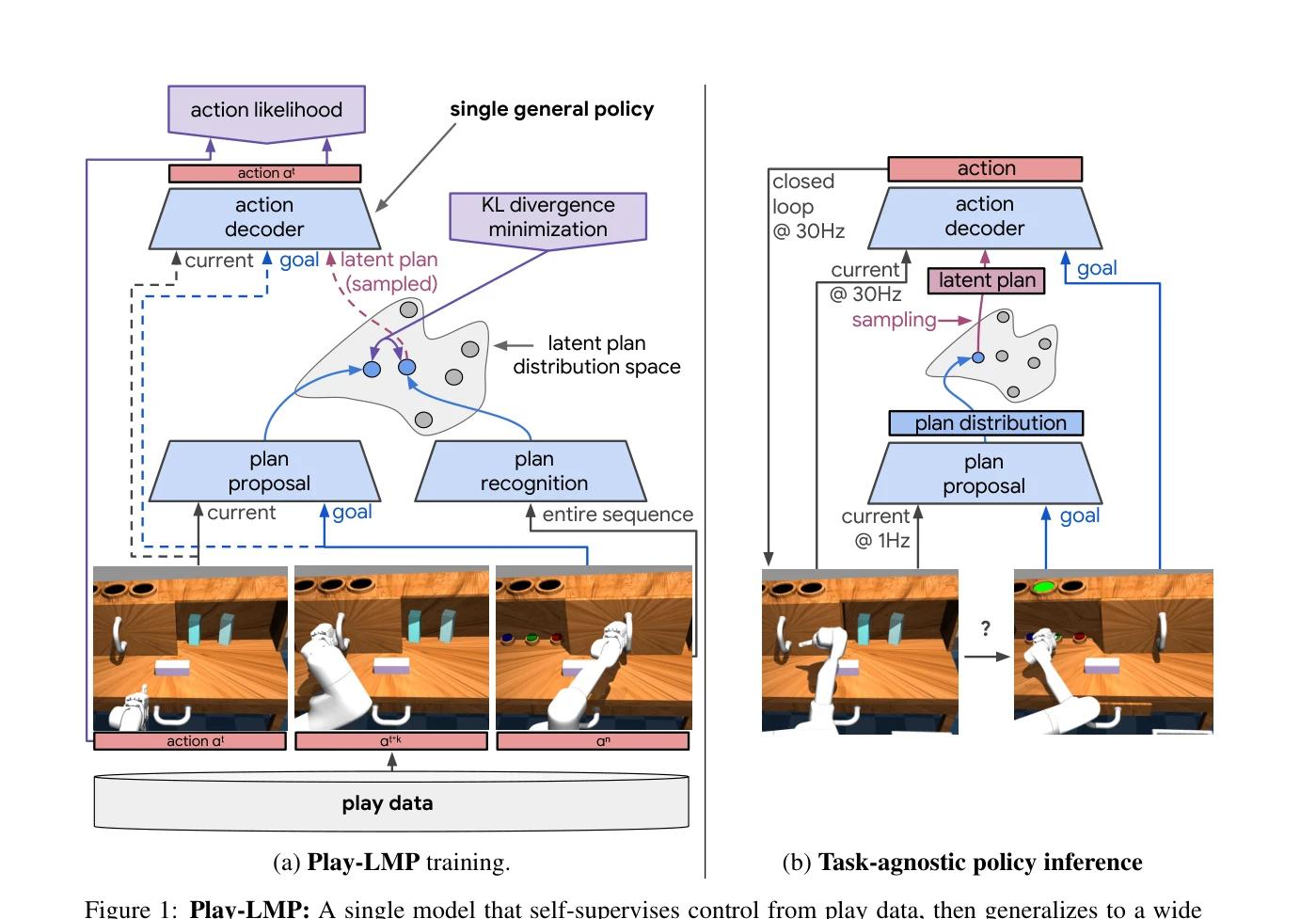
Figure 1: Play-LMP: A single model that self-supervises control from play data, then generalizes to a wide
인간의 비지도 원격조종 플레이 데이터로부터 자기감독 학습을 통해 잠재 계획 공간에서 행동을 조직화하고 재사용하여 다양한 조작 작업을 수행할 수 있는 Play-LMP 방법을 제안한다.
저자: Corey Lynch, Mohi Khansari, Ted Xiao, Vikash Kumar, Jonathan Tompson, Sergey Levine, Pierre Sermanet | 날짜: 2019-03-05 | URL: https://arxiv.org/abs/1903.01973 📄 PDF
Figure 1: Play-LMP: A single model that self-supervises control from play data, then generalizes to a wide
인간의 비지도 원격조종 플레이 데이터로부터 자기감독 학습을 통해 잠재 계획 공간에서 행동을 조직화하고 재사용하여 다양한 조작 작업을 수행할 수 있는 Play-LMP 방법을 제안한다.
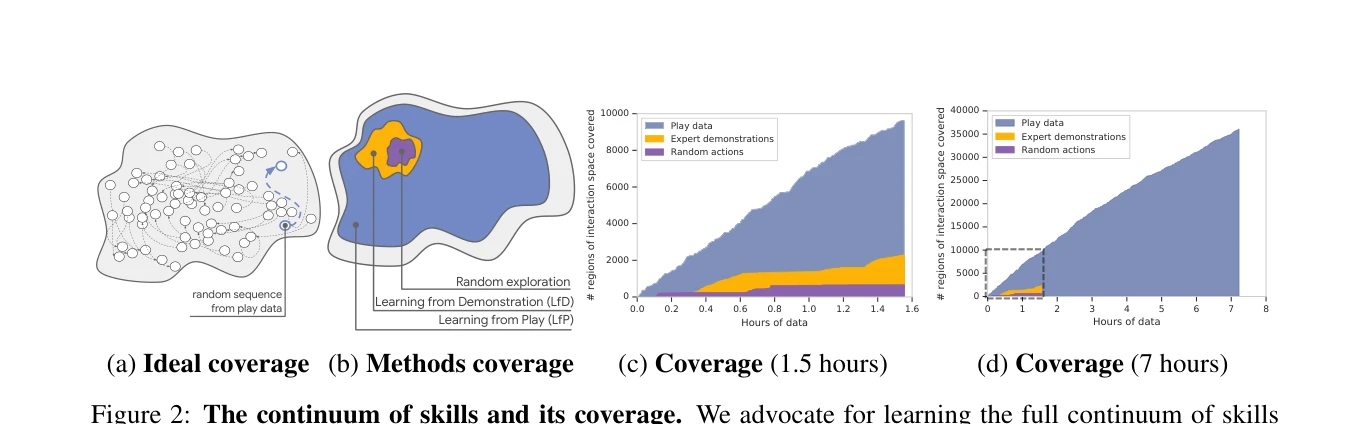
Figure 2: The continuum of skills and its coverage. We advocate for learning the full continuum of skills
Figure 1: Play-LMP: A single model that self-supervises control from play data, then generalizes to a wide
총평: 플레이 데이터라는 새로운 감독 신호를 통해 로봇 학습의 확장성 문제를 혁신적으로 접근했으며, 이원 인코더 구조와 자기감독 학습의 결합은 다중양식 제어 문제를 우아하게 해결한다. 시뮬레이션 환경에서의 강력한 실증적 결과와 명확한 제시에도 불구하고, 실제 로봇 적용을 통한 검증이 실용적 영향력을 판단하는 데 중요할 것으로 보인다.