Essence
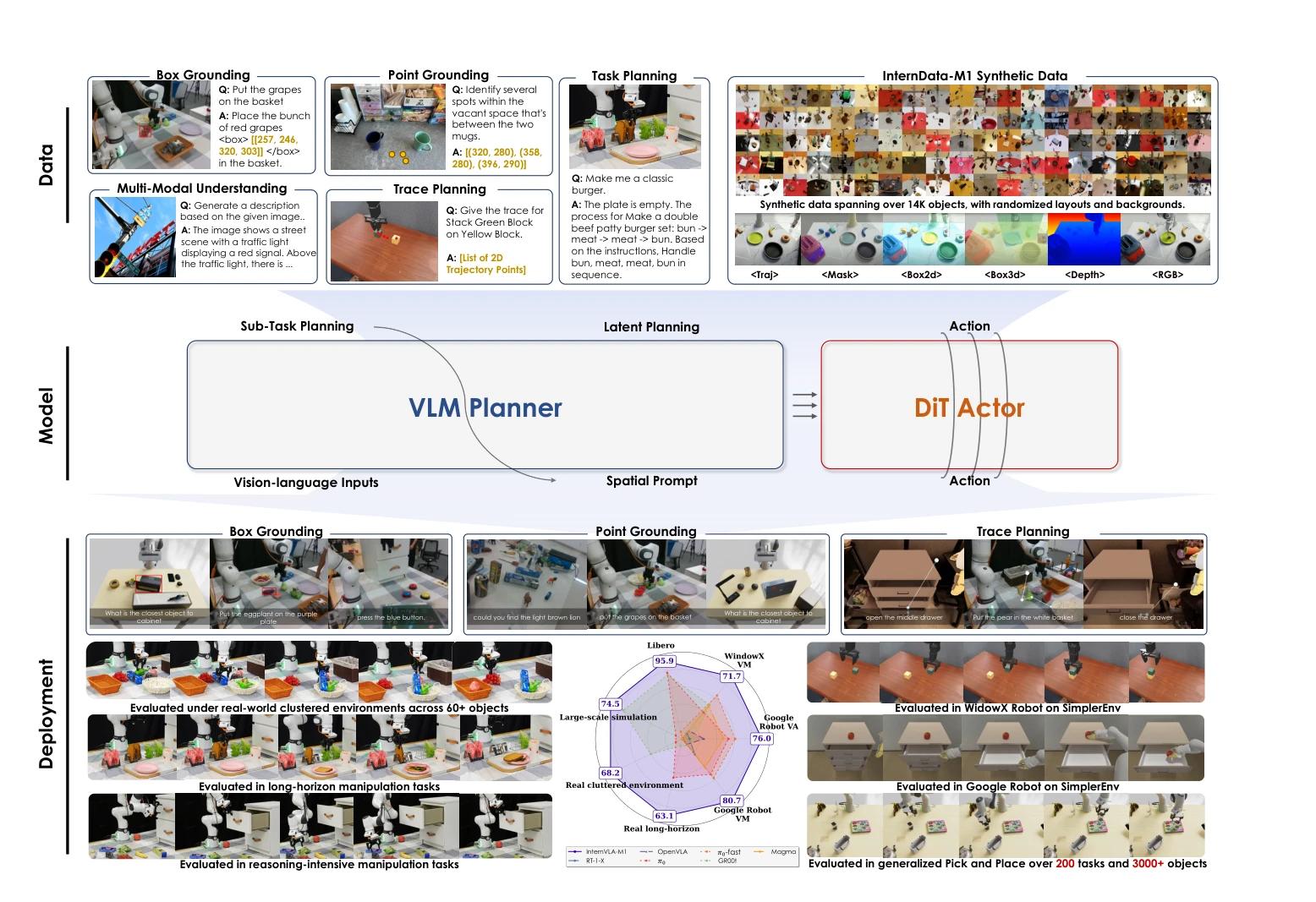
Figure 1. InternVLA-M1 integrates spatial grounding into the vision–language–action training pipeline.
InternVLA-M1은 공간 그라운딩을 시각-언어-행동 학습의 중심 연결고리로 활용하여, 지시 따르기 로봇의 확장 가능한 일반 지능을 구현한 통합 프레임워크이다.
저자: Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, Yang Tian, Bin Wang, Bolun Wang, Fangjing Wang, Hanqing Wang, Tai Wang, Ziqin Wang, Xueyuan Wei, Chao Wu, Shuai Yang, Jinhui Ye, Junqiu Yu, Jia Zeng, Jingjing Zhang, Jinyu Zhang, Shi Zhang, Feng Zheng, Bowen Zhou, Yangkun Zhu | 날짜: 2025-10-15 | URL: https://arxiv.org/abs/2510.13778 📄 PDF
Figure 1. InternVLA-M1 integrates spatial grounding into the vision–language–action training pipeline.
InternVLA-M1은 공간 그라운딩을 시각-언어-행동 학습의 중심 연결고리로 활용하여, 지시 따르기 로봇의 확장 가능한 일반 지능을 구현한 통합 프레임워크이다.
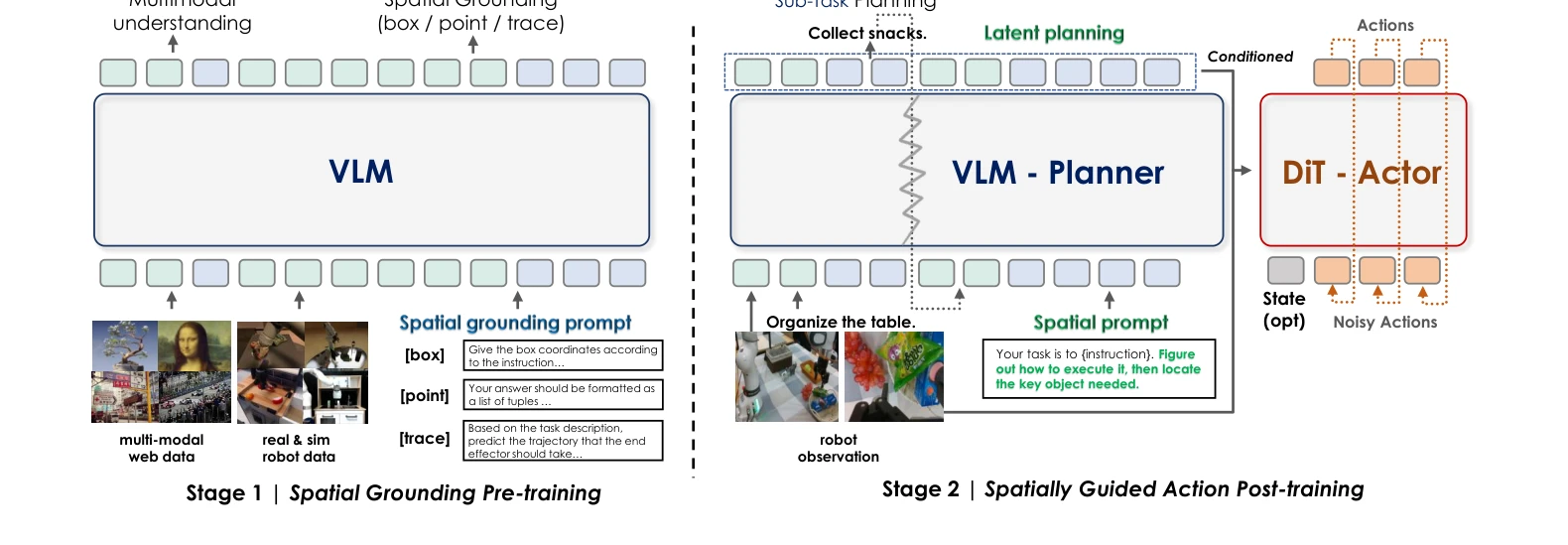
Figure 2. Overview of InternVLA-M1. InternVLA-M1 adopts a spatially guided two-stage training
Figure 2. Overview of InternVLA-M1. InternVLA-M1 adopts a spatially guided two-stage training
총평: InternVLA-M1은 공간 그라운딩을 중추로 하는 이중 시스템 설계로 instruction-following과 embodied control 간 명확한 인터페이스를 제시하며, 광범위한 벤치마크에서 일관된 성능 향상과 확장성을 입증한 매우 견고한 연구이다.