Essence
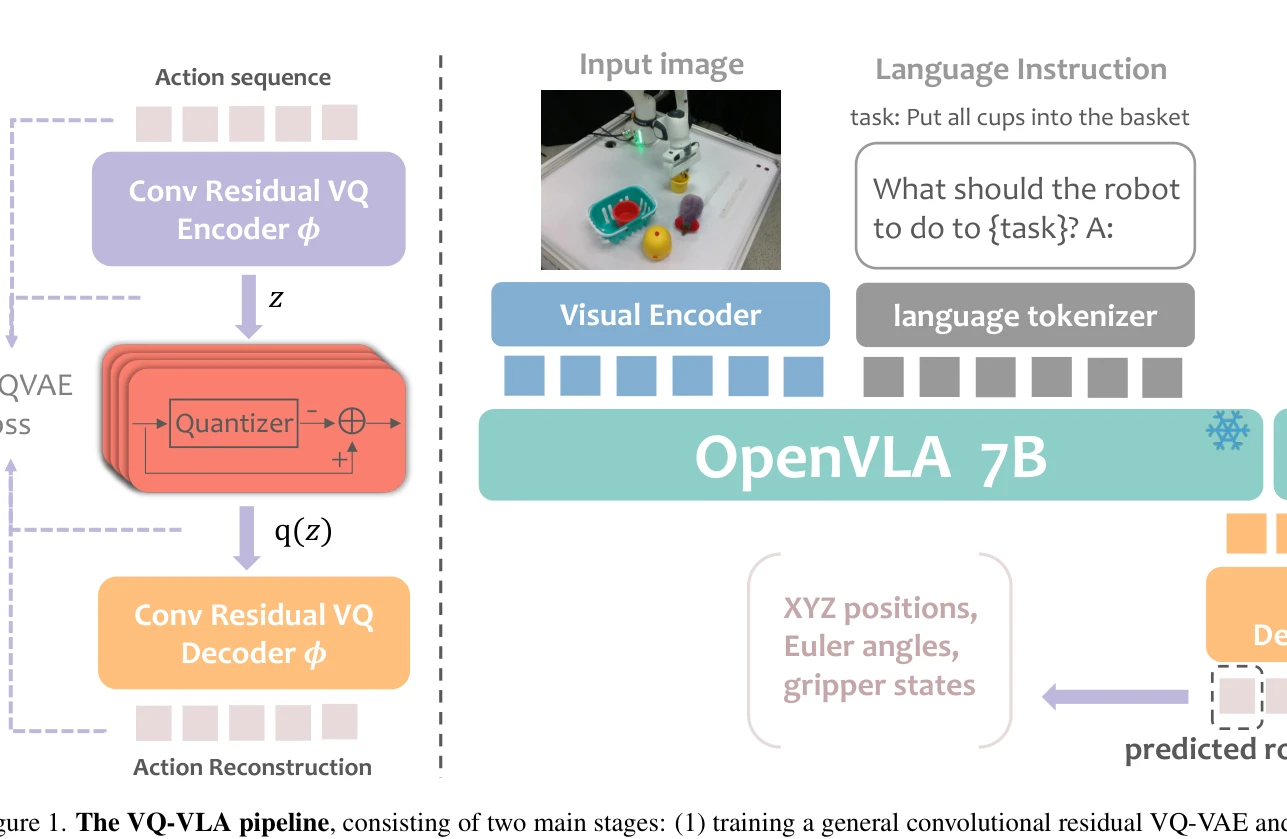
Figure 1. The VQ-VLA pipeline, consisting of two main stages: (1) training a general convolutional residual VQ-VAE and (
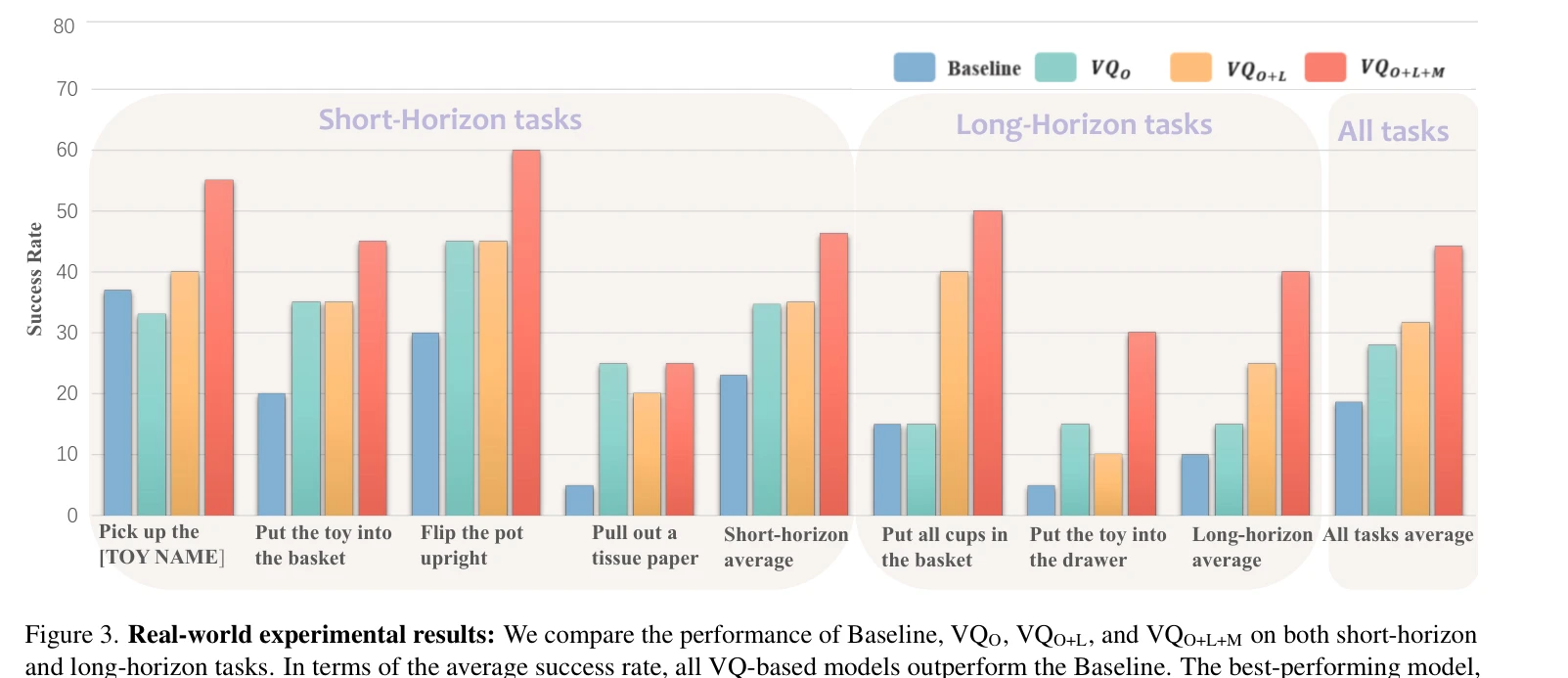
100배 이상의 대규모 action trajectory 데이터셋을 활용하여 vector quantization 기반 action tokenizer를 학습하고, 이를 Vision-Language-Action 모델에 통합하여 추론 속도, 동작 부드러움, 장기 계획 능력을 향상시킨다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 action tokenization을 대규모 데이터셋으로 확장하는 실용적이고 효과적인 방법론을 제시하며, synthetic-real 데이터 간 minimal domain gap이라는 중요한 발견을 통해 scalable embodied intelligence 시스템 구현의 길을 열었다. 실험 결과와 이론적 근거가 충분하고 VLA 모델의 성능과 효율성을 동시에 향상시키는 점에서 높은 실용성과 학술적 가치를 지닌다.