저자: Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, Jun Zhu | 날짜: 2024-10-10 | URL: https://arxiv.org/abs/2410.07864 📄 PDF
Essence
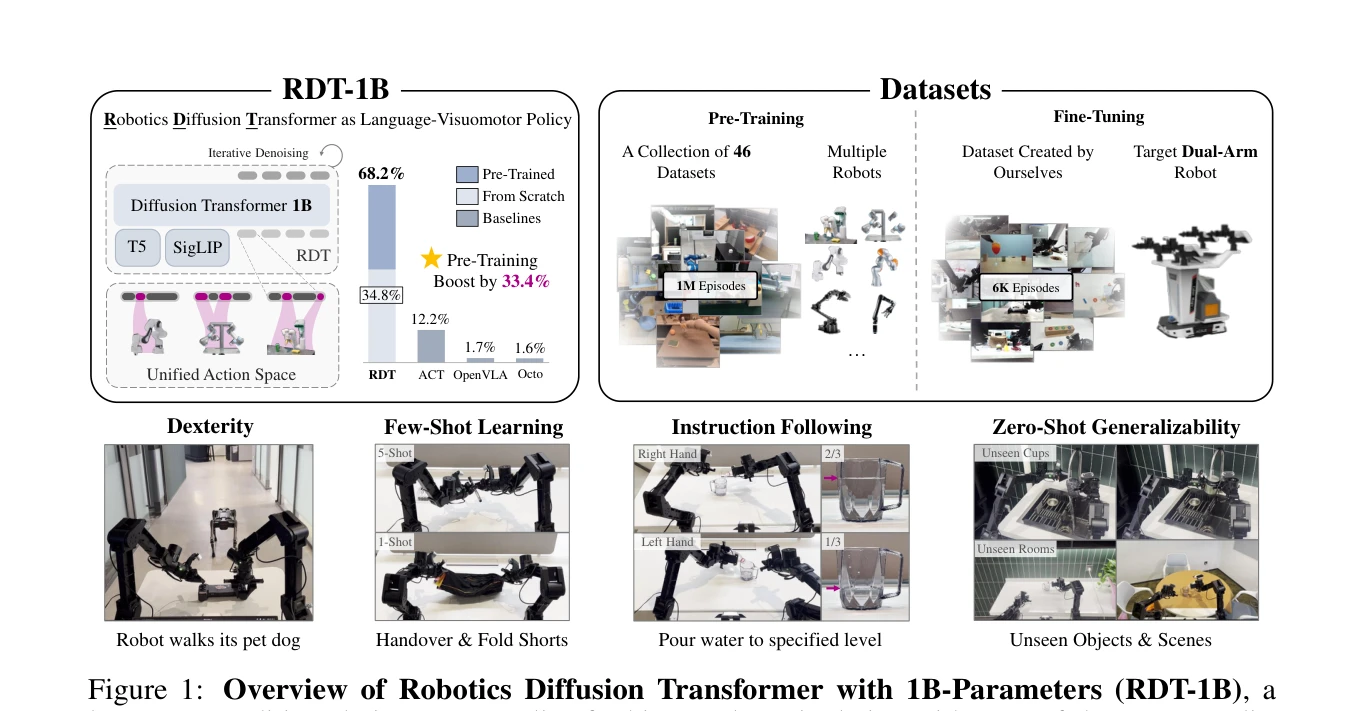
Figure 1: Overview of Robotics Diffusion Transformer with 1B-Parameters (RDT-1B), a
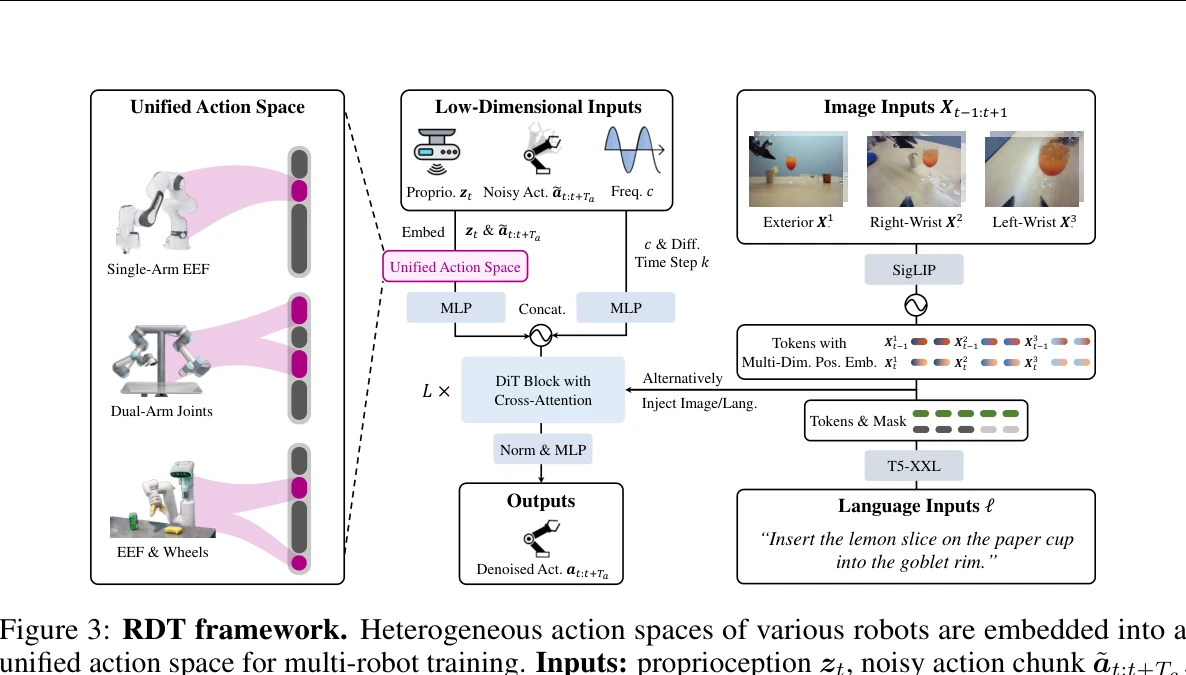
bimanual manipulation을 위한 1.2B 파라미터 규모의 diffusion foundation model인 RDT를 제시하며, 다중 로봇 데이터셋 사전학습과 physically interpretable unified action space를 통해 높은 일반화 성능을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: RDT-1B는 bimanual manipulation을 위한 diffusion foundation model의 획기적 사례로, physically interpretable unified action space 개념과 맞춤형 architecture 설계를 통해 multi-modality와 data heterogeneity 문제를 효과적으로 해결하였으며, 대규모 사전학습과 강력한 실험 결과로 로봇 자동화의 실질적 진전을 보여준다.