Essence
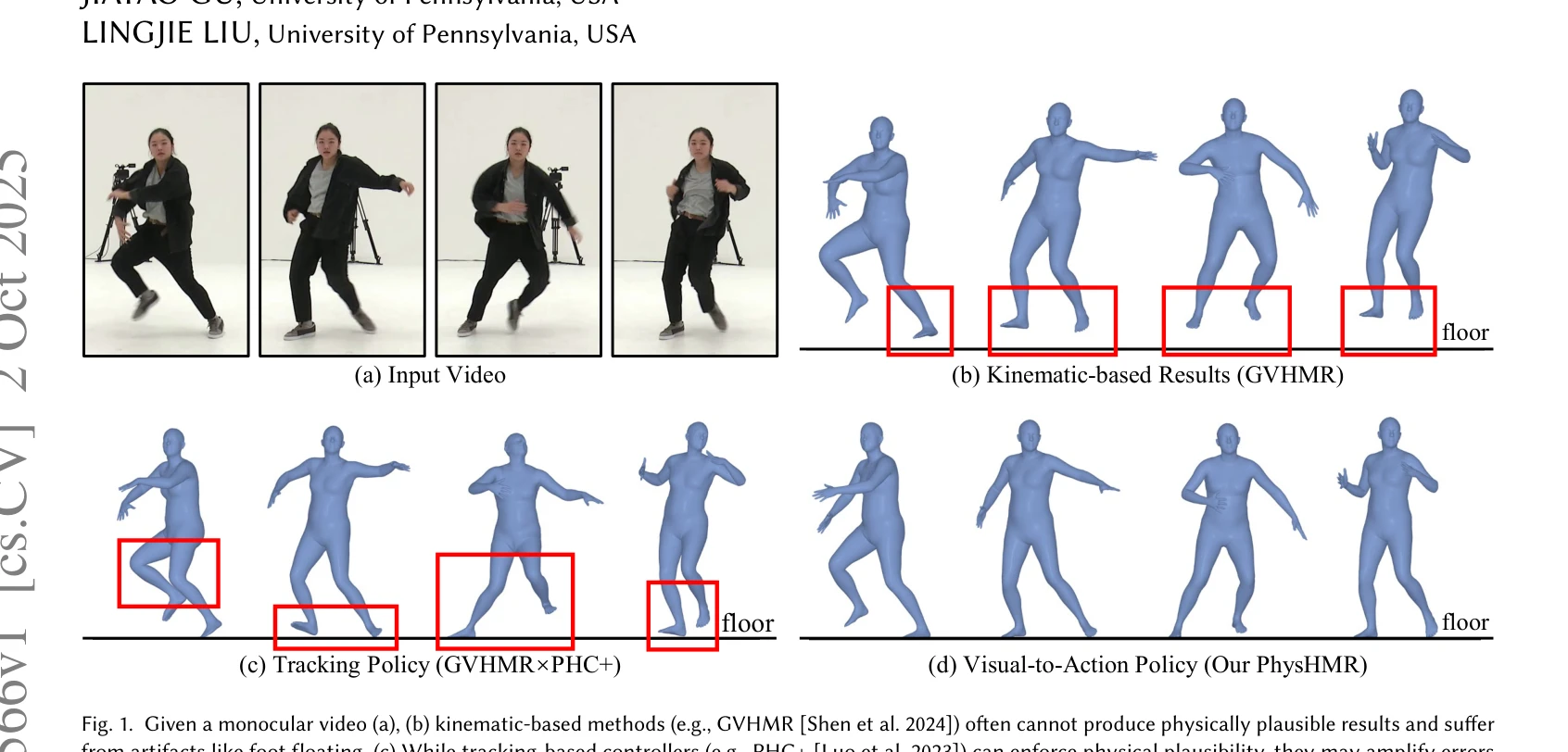
Fig. 1. Given a monocular video (a), (b) kinematic-based methods (e.g., GVHMR [Shen et al. 2024]) often cannot produce p
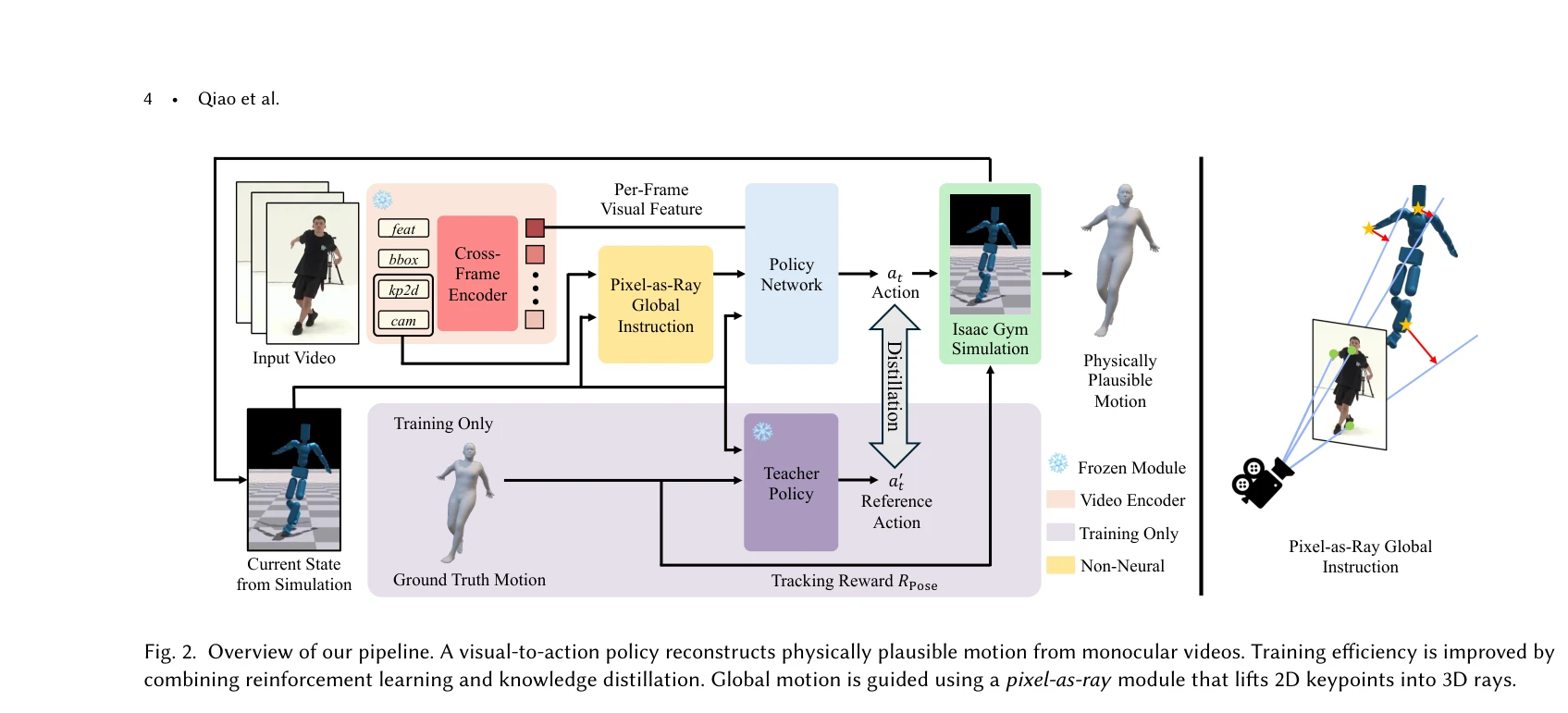
PhysHMR은 모노큘러 비디오로부터 물리적으로 타당한 인간 동작 재구성을 위해 비전-기반 휴머노이드 제어 정책을 직접 학습하는 통합 프레임워크이다. 기존의 두 단계 방식(운동학 기반 추정 + 물리 후처리)과 달리, 시각 정보와 물리 제약을 단일 정책 네트워크에서 함께 추론한다.