Essence
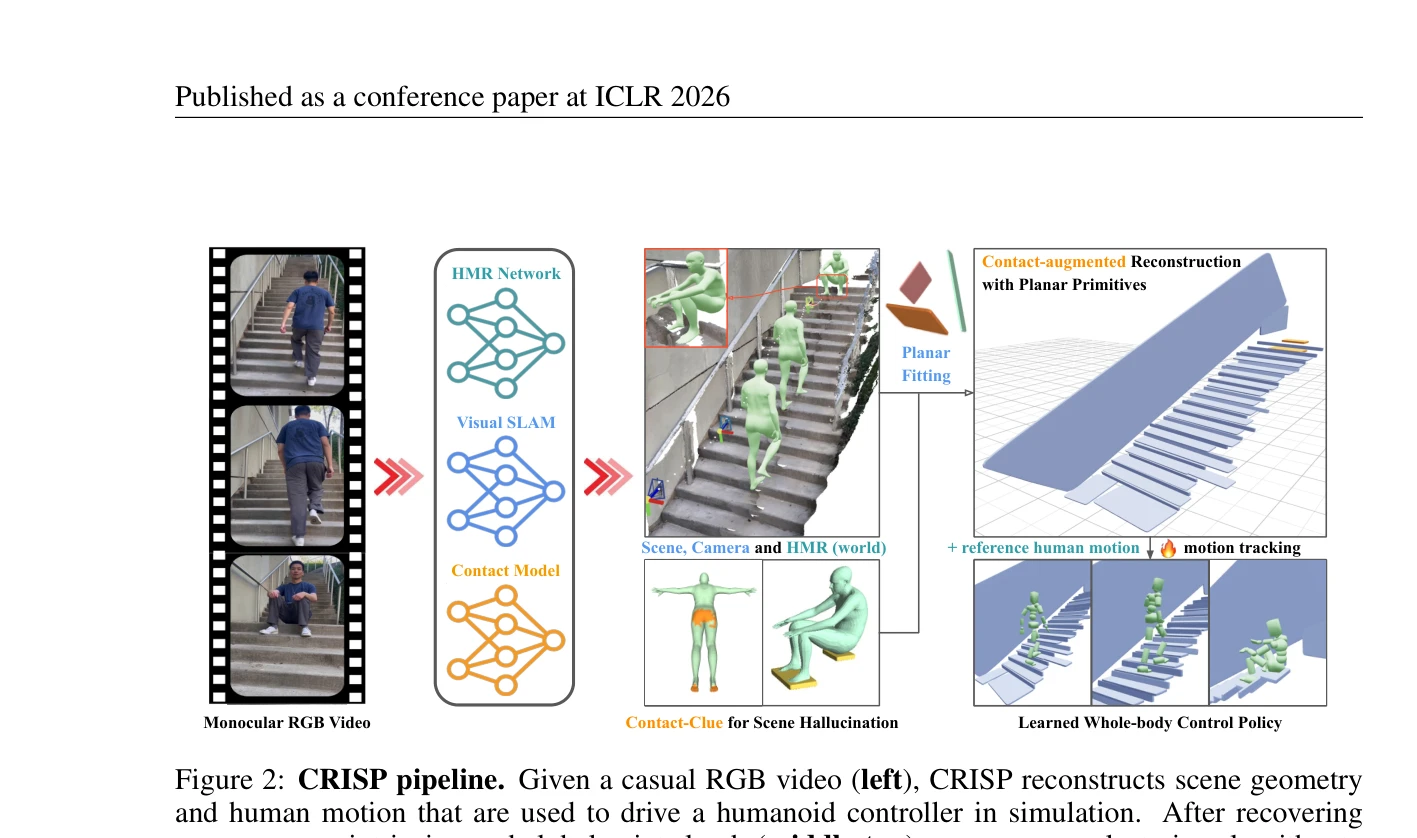
Figure 2: CRISP pipeline. Given a casual RGB video (left), CRISP reconstructs scene geometry
단안 비디오에서 planar primitive 기반 scene geometry 복원과 human motion 추정을 통해 물리 시뮬레이션 가능한 human-scene reconstruction을 수행하는 real-to-sim 파이프라인을 제안한다.
저자: Zihan Wang, Jiashun Wang, Jeff Tan, Yiwen Zhao, Jessica Hodgins, Shubham Tulsiani, Deva Ramanan | 날짜: 2025-12-16 | URL: https://arxiv.org/abs/2512.14696 📄 PDF
Figure 2: CRISP pipeline. Given a casual RGB video (left), CRISP reconstructs scene geometry
단안 비디오에서 planar primitive 기반 scene geometry 복원과 human motion 추정을 통해 물리 시뮬레이션 가능한 human-scene reconstruction을 수행하는 real-to-sim 파이프라인을 제안한다.
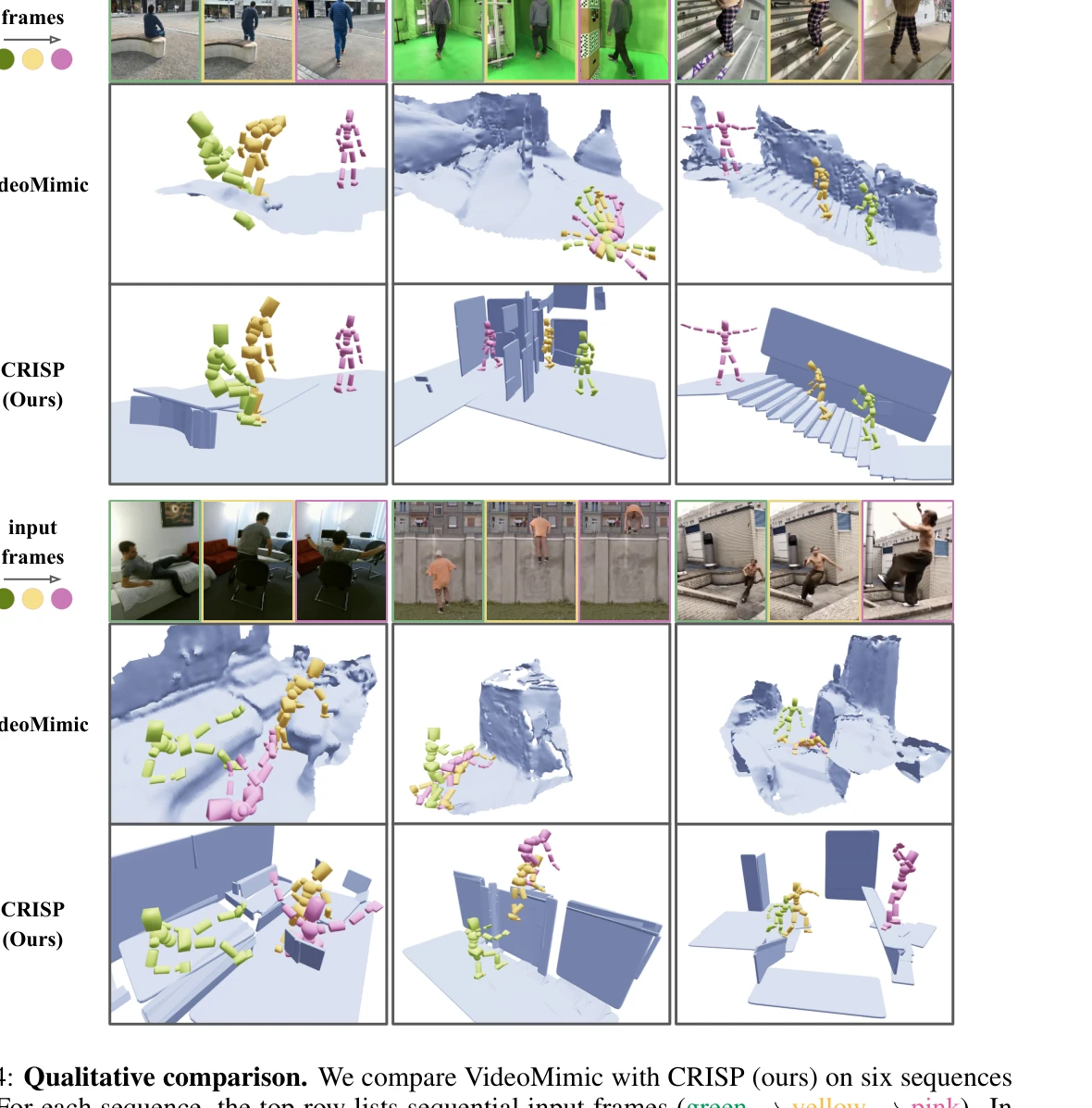
Figure 4: Qualitative comparison. We compare VideoMimic with CRISP (ours) on six sequences
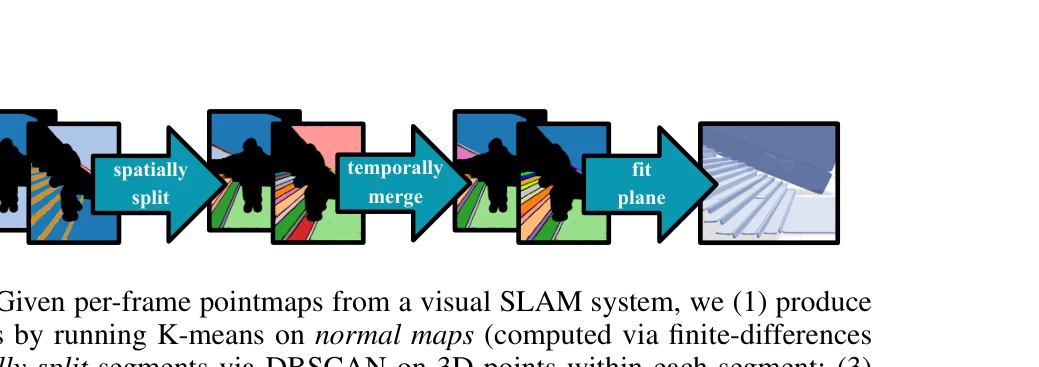
Figure 3: Planar fitting. Given per-frame pointmaps from a visual SLAM system, we (1) produce
총평: CRISP는 planar primitive 기반의 간단하면서도 효과적인 real-to-sim 파이프라인으로, 기존 human-scene reconstruction의 근본적 문제(simulation incompatibility)를 physics 기반 검증으로 해결하며, substantial empirical improvement와 in-the-wild generalization을 통해 embodied AI 분야에 실질적 기여를 한다.