Essence
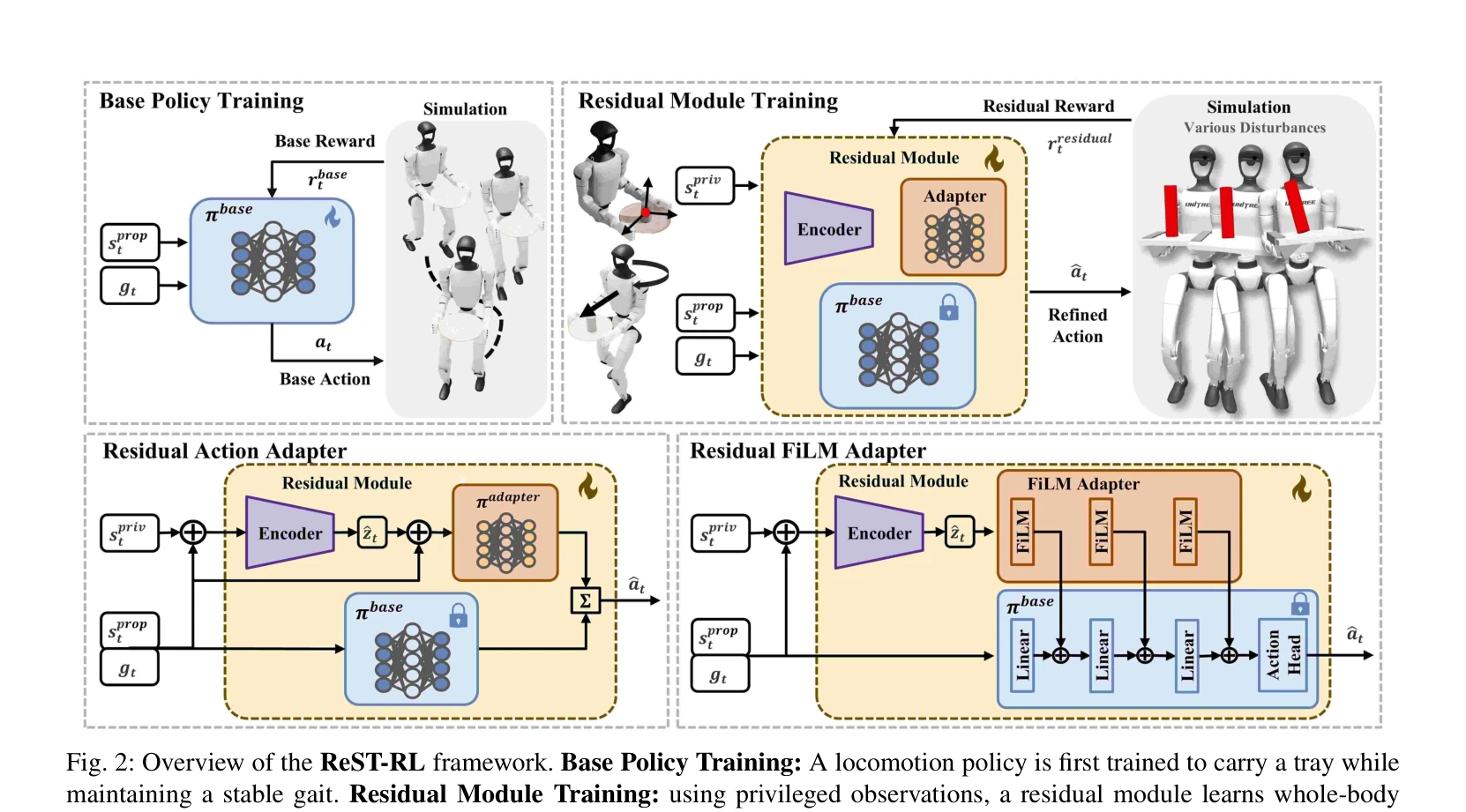
Fig. 2: Overview of the ReST-RL framework. Base Policy Training: A locomotion policy is first trained to carry a tray wh
ReST-RL은 사전학습된 이족 보행 정책에 잔차 모듈을 추가하여 휴머노이드 로봇이 동적 보행 중 트레이 위의 불안정한 물체를 안정적으로 운반할 수 있도록 하는 계층적 강화학습 아키텍처이다.
저자: Anlun Huang, Zhenyu Wu, Soofiyan Atar, Yuheng Zhi, Michael Yip | 날짜: 2026-03-11 | DOI: 10.48550/arXiv.2603.10306 📄 PDF
Fig. 2: Overview of the ReST-RL framework. Base Policy Training: A locomotion policy is first trained to carry a tray wh
ReST-RL은 사전학습된 이족 보행 정책에 잔차 모듈을 추가하여 휴머노이드 로봇이 동적 보행 중 트레이 위의 불안정한 물체를 안정적으로 운반할 수 있도록 하는 계층적 강화학습 아키텍처이다.
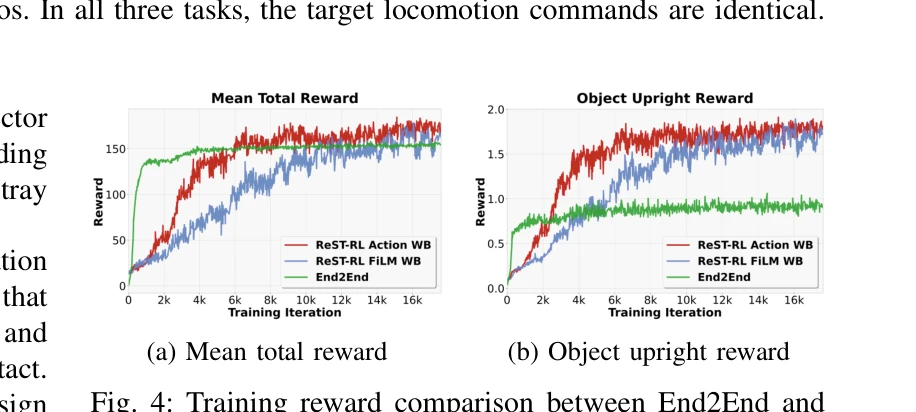
Fig. 4: Training reward comparison between End2End and
Fig. 2: Overview of the ReST-RL framework. Base Policy Training: A locomotion policy is first trained to carry a tray wh
총평: ReST-RL은 보행 안정성을 보존하면서 payload 안정화를 분리 학습하는 우아한 설계로, 휴머노이드 로봇의 실제 서비스 응용(식음료 배송, 의료 기구 운반)에 필수적인 신뢰성 높은 물체 운반을 처음 성공적으로 시연했다.