Essence
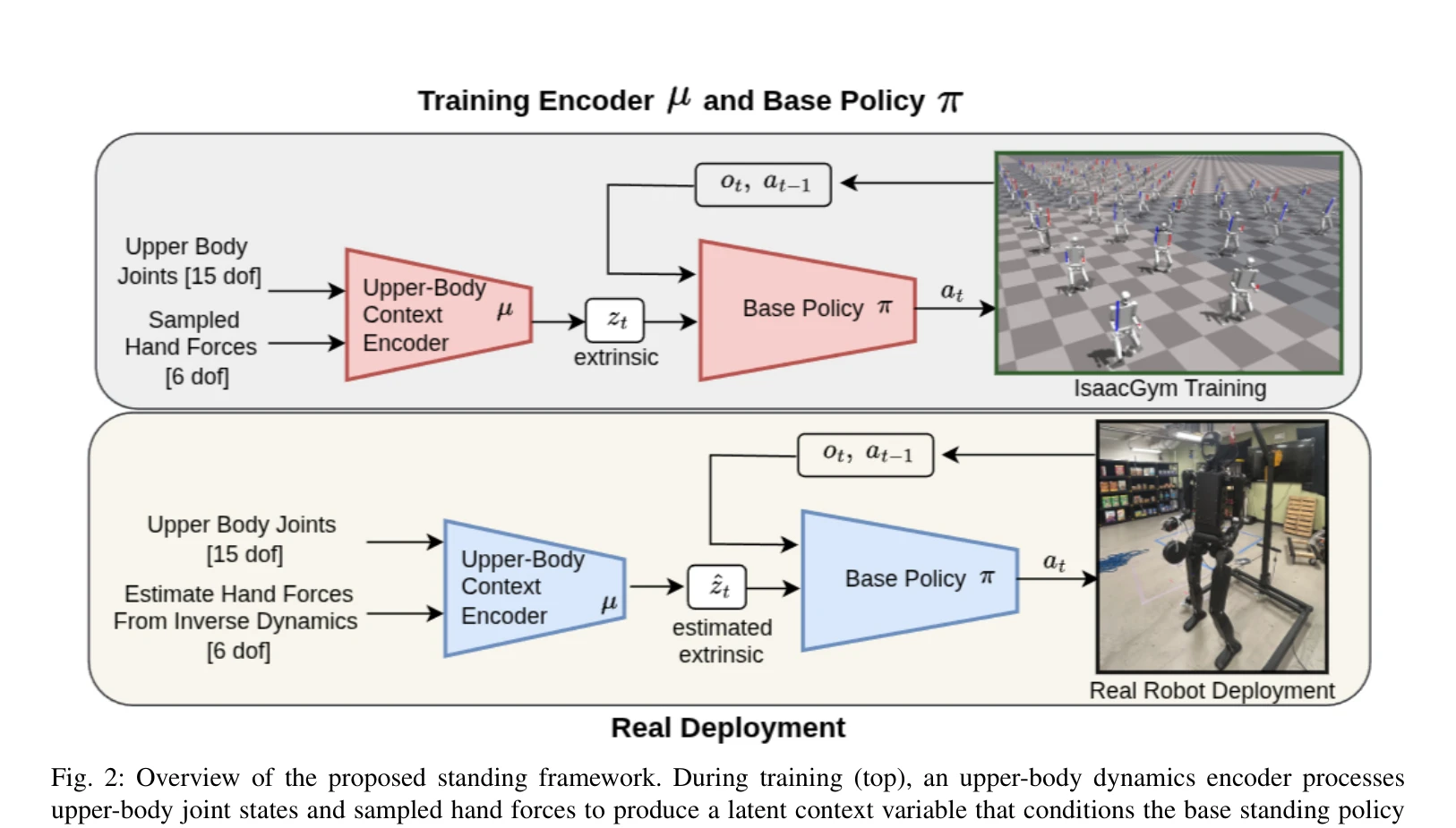
Fig. 2: Overview of the proposed standing framework. During training (top), an upper-body dynamics encoder processes
FAME는 양팔 조작 시 외부 손 힘으로 인한 균형 교란을 해결하기 위해, 상체 관절 구성과 양팔 상호작용 힘을 인코딩하는 latent context에 조건화된 RL 정책을 학습한다.
저자: Niraj Pudasaini, Yutong Zhang, Jensen Lavering, Alessandro Roncone, Nikolaus Correll | 날짜: 2026-03-09 | URL: https://arxiv.org/abs/2603.08961 📄 PDF
Fig. 2: Overview of the proposed standing framework. During training (top), an upper-body dynamics encoder processes
FAME는 양팔 조작 시 외부 손 힘으로 인한 균형 교란을 해결하기 위해, 상체 관절 구성과 양팔 상호작용 힘을 인코딩하는 latent context에 조건화된 RL 정책을 학습한다.
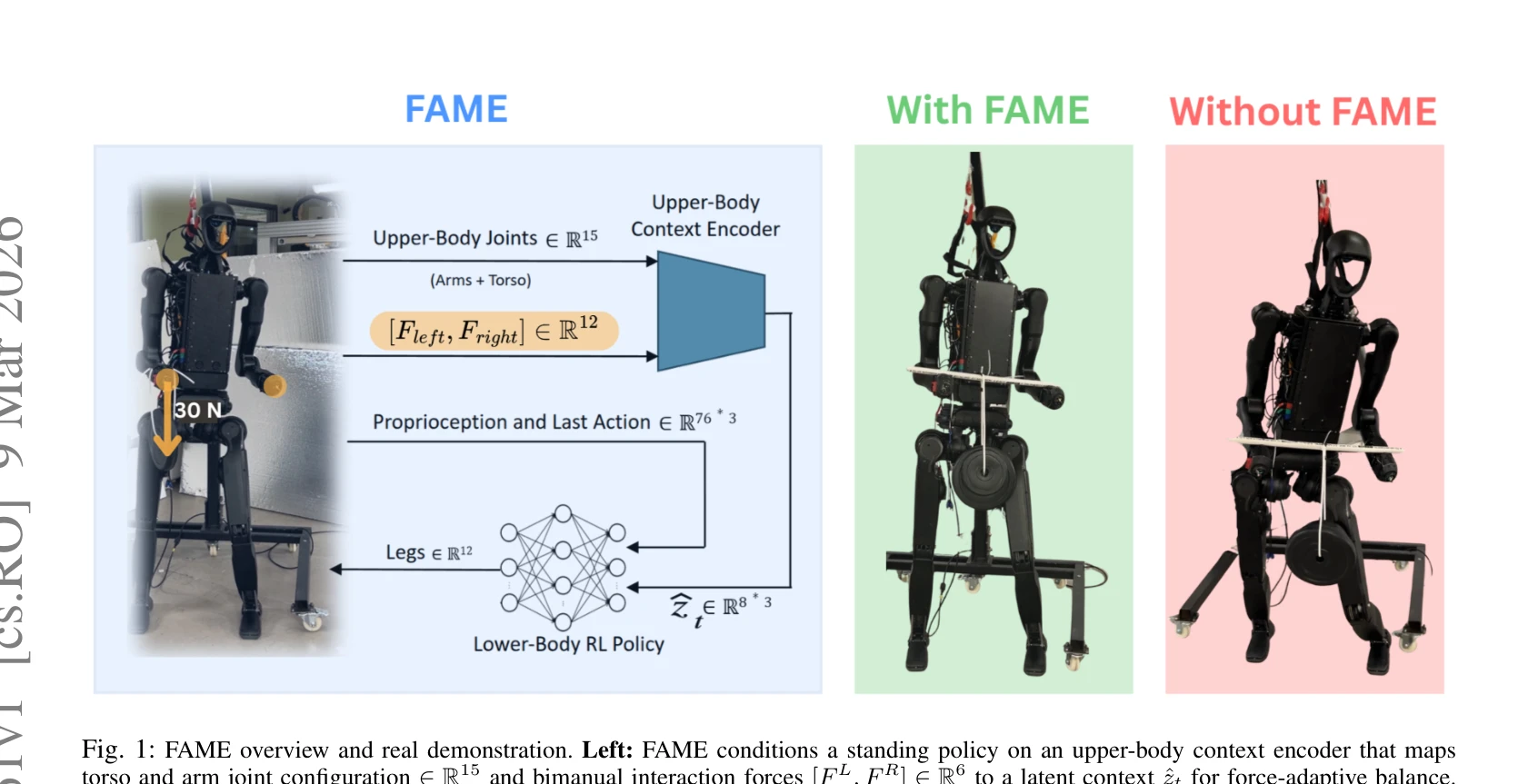
Fig. 1: FAME overview and real demonstration. Left: FAME conditions a standing policy on an upper-body context encoder t
Fig. 2: Overview of the proposed standing framework. During training (top), an upper-body dynamics encoder processes
총평: FAME는 latent context adaptation을 양팔 조작 중 balance 문제에 창의적으로 적용하며, 센서 불필요 배포와 실세계 검증으로 실용적 기여를 한다. 다만 sim-to-real 격차와 힘 추정 정확도 분석이 보강되면 더욱 강력해질 것이다.