Essence
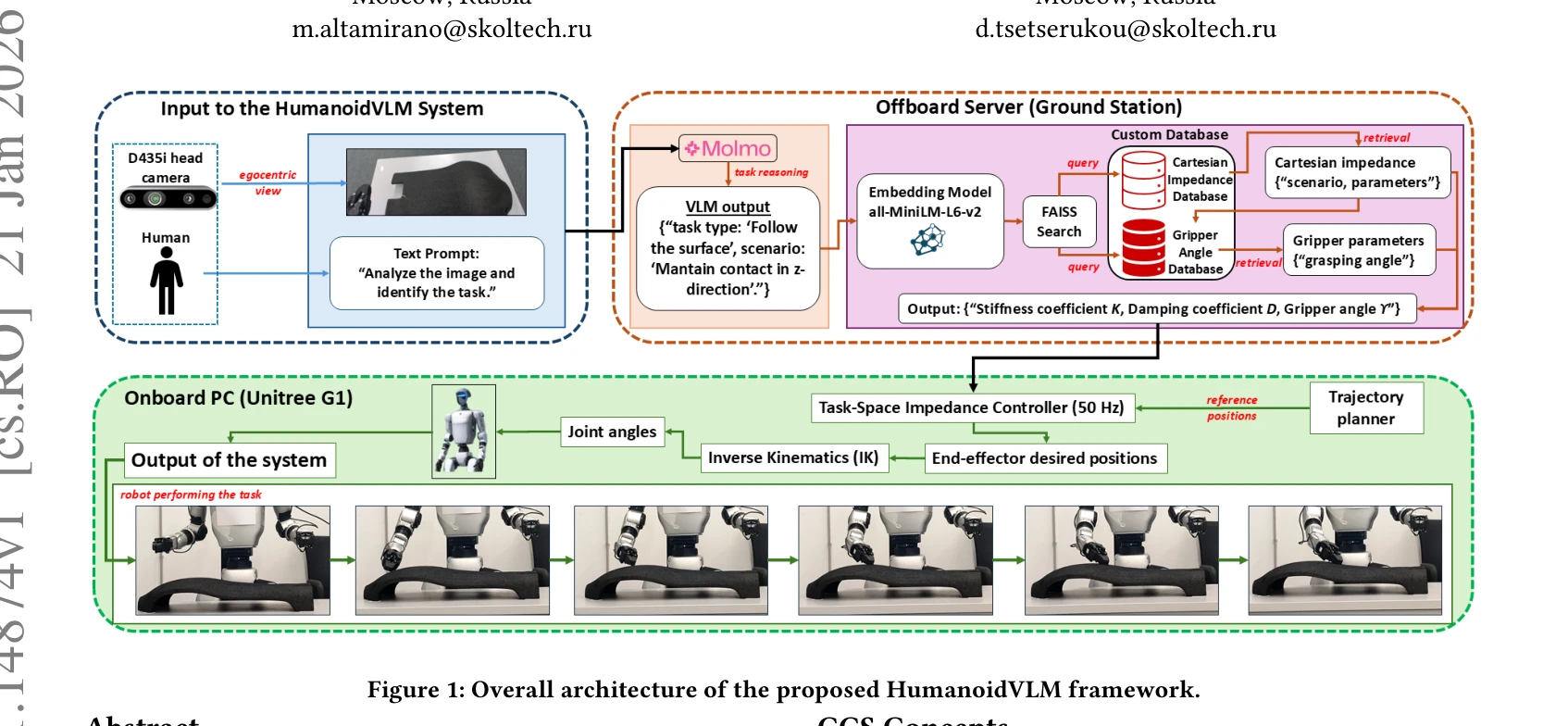
Figure 1: Overall architecture of the proposed HumanoidVLM framework.
HumanoidVLM은 vision-language model과 retrieval-augmented generation을 결합하여 휴머노이드 로봇이 egocentric 이미지로부터 task-specific impedance parameters와 gripper configuration을 자동으로 선택하는 적응형 조작 프레임워크이다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
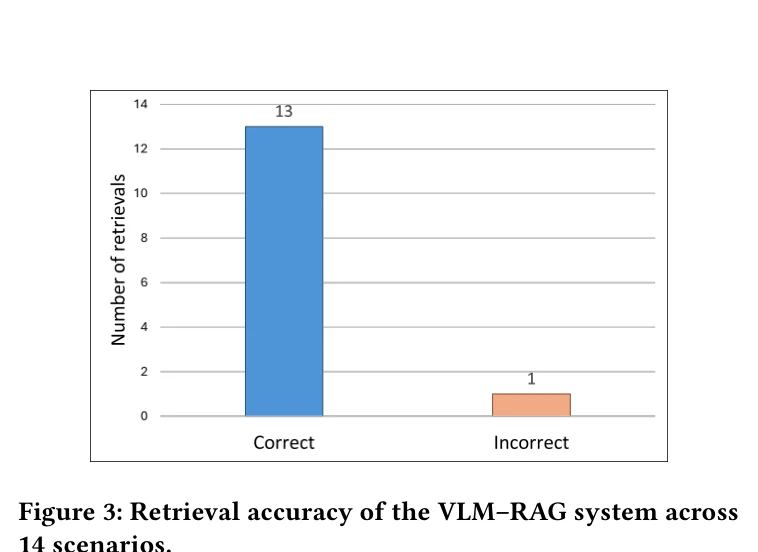
총평: 본 논문은 VLM과 RAG를 humanoid manipulation에 효과적으로 적용하여 semantic perception과 compliant control을 처음 체계적으로 연결했으며, 높은 retrieval 정확도와 실제 로봇 실험을 통해 타당성을 입증했다. 다만 고정된 database 규모와 sensor 제약이 향후 확장성을 제한하는 점이 개선 대상이다.