Essence
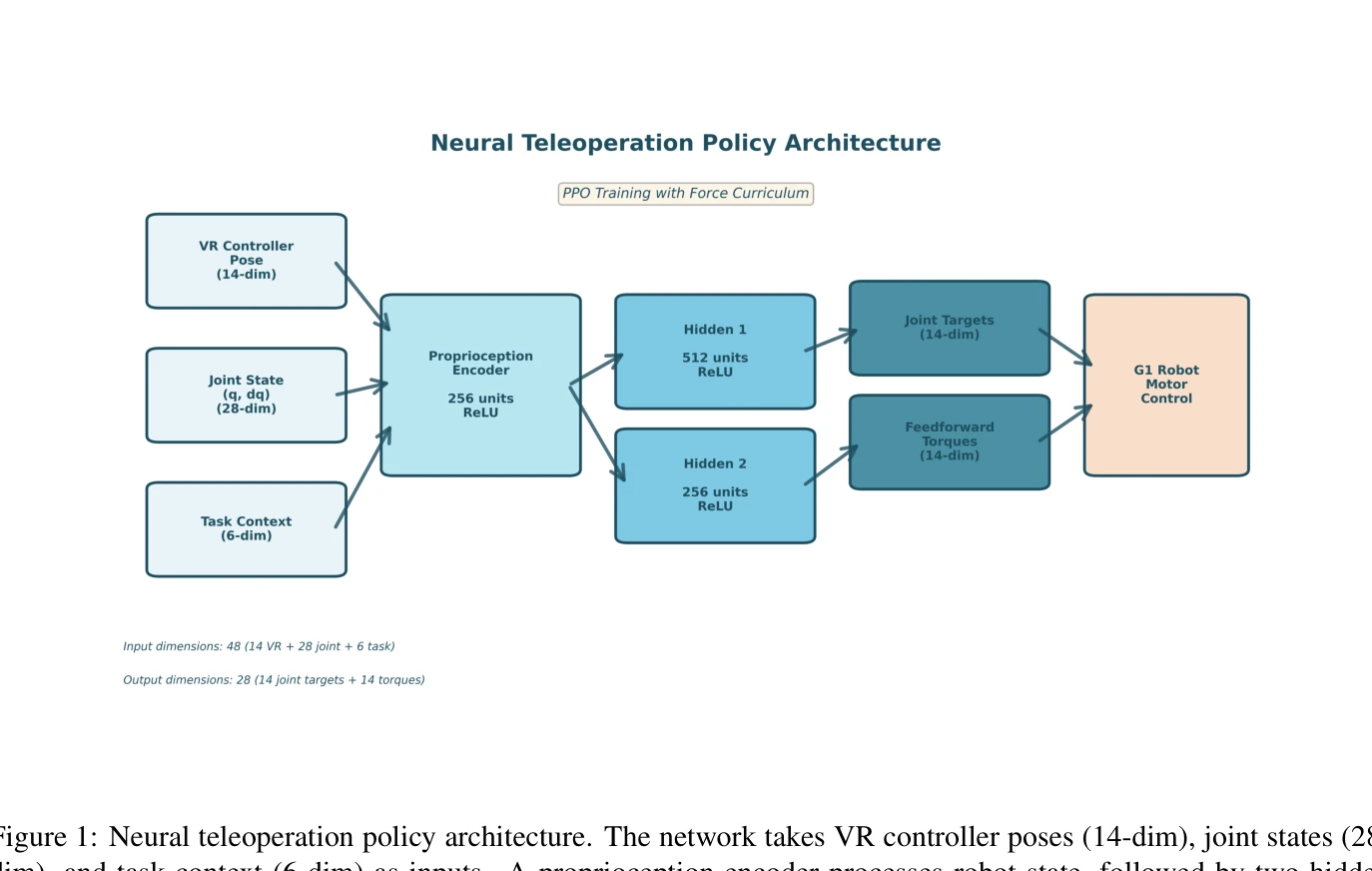
Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-
VR 텔레오퍼레이션에서 전통적인 IK+PD 파이프라인을 RL 기반 신경망 정책으로 대체하여 힘 적응, 궤적 부드러움, 사용자 적응을 동시에 달성하는 학습 기반 프레임워크를 제안한다.
저자: Sanjar Atamuradov | 날짜: 2025-11-15 | URL: https://arxiv.org/abs/2511.12390 📄 PDF
Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-
VR 텔레오퍼레이션에서 전통적인 IK+PD 파이프라인을 RL 기반 신경망 정책으로 대체하여 힘 적응, 궤적 부드러움, 사용자 적응을 동시에 달성하는 학습 기반 프레임워크를 제안한다.
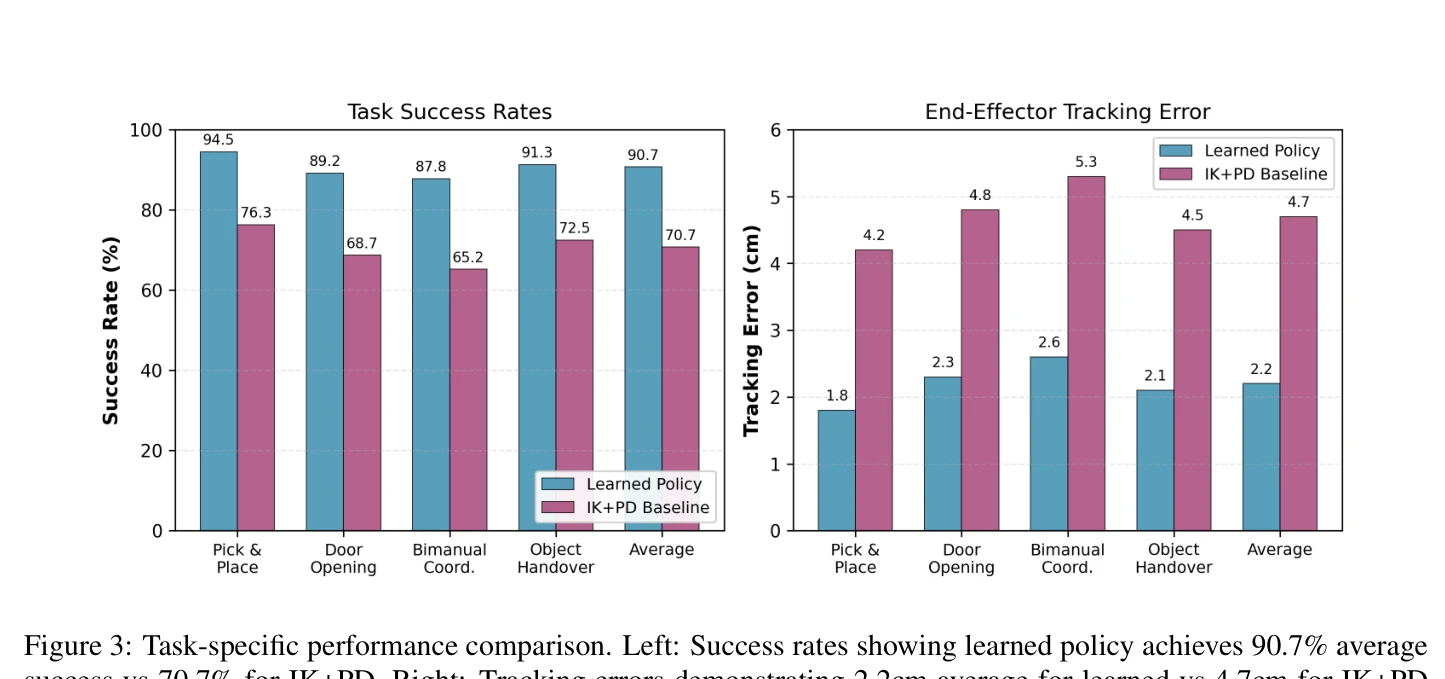
Figure 3 provides a detailed breakdown of performance
Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-
총평: 학습 기반 신경망 정책으로 VR 텔레오퍼레이션의 근본적 한계를 해결하고 명확한 성능 향상을 보여주는 실질적으로 가치 있는 연구이며, 모방 학습과 교과 학습의 조합 설계가 우수하다.