Essence
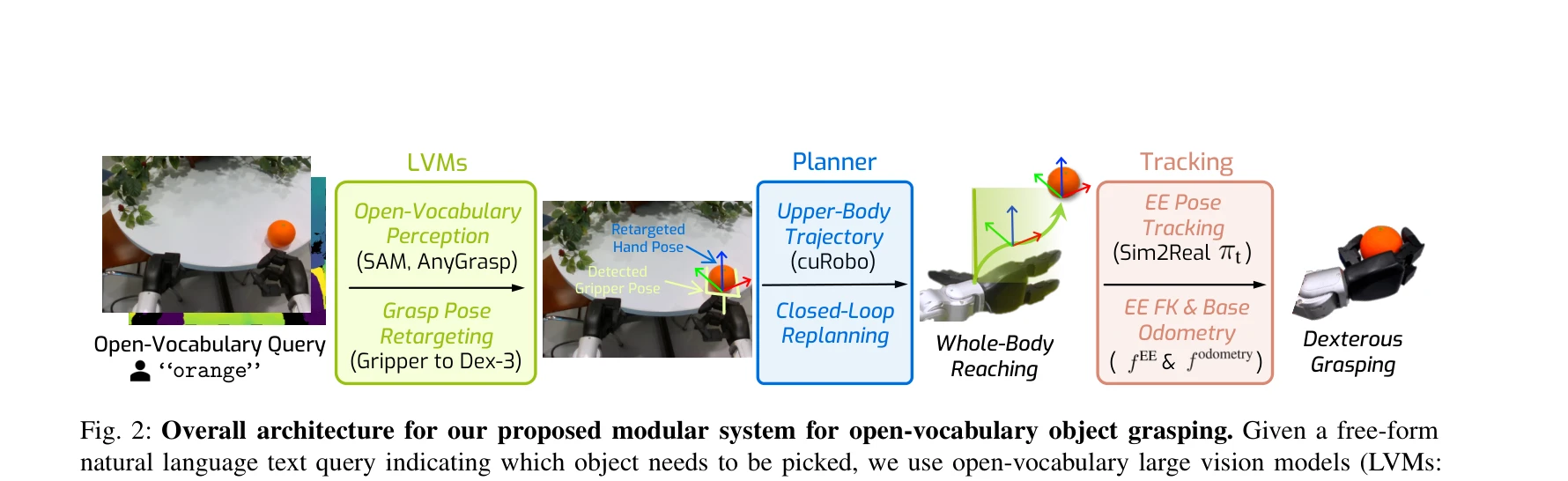
Fig. 2: Overall architecture for our proposed modular system for open-vocabulary object grasping. Given a free-form
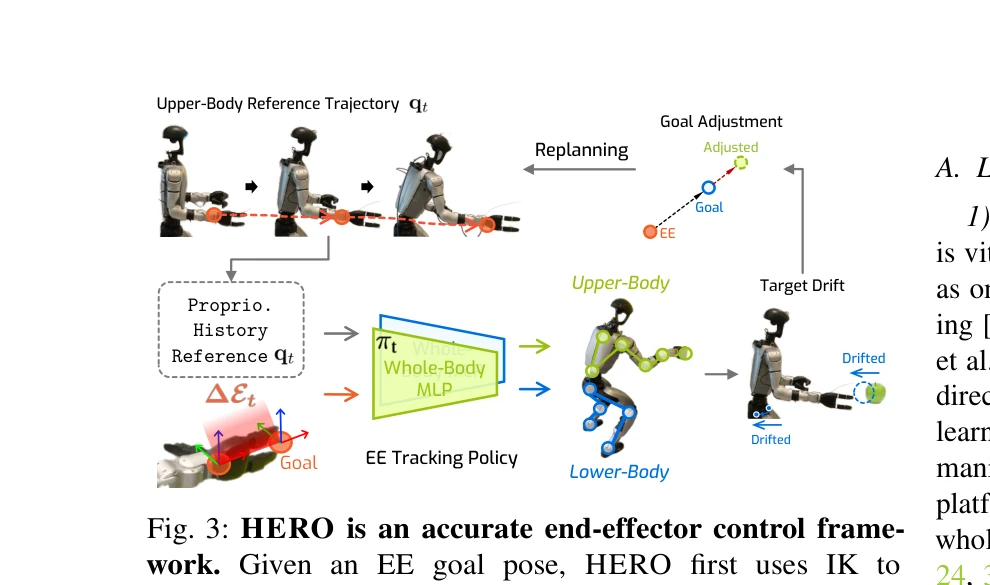
HERO 시스템은 정확한 end-effector 추적 정책과 대규모 비전 모델을 결합하여 휴머노이드 로봇이 미지의 환경에서 임의의 일상용품을 자율적으로 집을 수 있게 한다. End-effector 추적 오차를 3.2배 감소시키고 83.8%의 성공률을 달성했다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 정확한 end-effector 제어의 기술적 난제를 classical robotics와 학습 기반 모듈의 창의적 결합으로 해결하고, 이를 통해 humanoid의 실제 환경 object manipulation을 처음으로 현실화했다. 모듈식 설계로 대규모 실제 데이터 수집 없이도 open-vocabulary 일반화를 달성한 점이 특히 의미 있으며, 83.8%의 실제 환경 성공률은 해당 분야의 significant advance를 나타낸다.