How
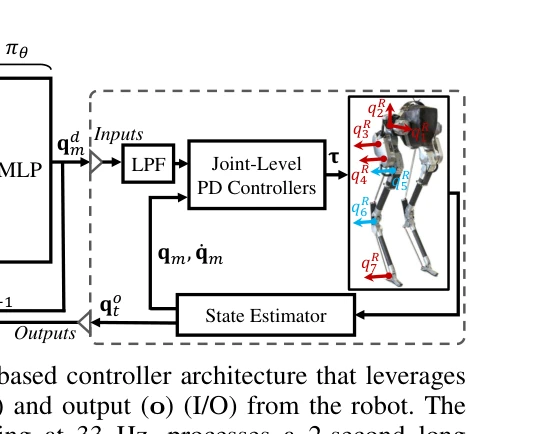
Fig. 3: The proposed RL-based controller architecture that leverages
- Robot proprioceptive I/O를 long-term 히스토리 인코더와 short-term 히스토리로 분리하여 정책 입력 구성
- Base 정책 학습 시 short-term 히스토리와 long-term 히스토리 인코더를 관절(joint) 학습하는 다중 단계 학습 전략 적용
- 환경 동역학 매개변수와 과제 명령(목표 속도, 점프 거리 등)을 광범위하게 무작위화하여 시뮬레이션 학습 수행
- 학습된 정책을 실제 Cassie 로봇에 직접 배포하여 추가 실제 세계 튜닝 없이 전이 학습 성공 검증
- 다양한 외부 방해(푸시, 경사지형 변화 등)에 대한 강건성 실험 및 적응성 분석 수행